超越幻觉的AI Agent故障模式

超越幻觉的AI Agent故障模式
AI会犯错,模型会产生幻觉,模型会编造东西——这些已经是众所周知的抱怨。然而,当涉及智能体工程(agentic engineering)时,这些认知几乎没什么实际用处。知道模型会犯错又能怎样?无非是不信任任何输出,或是对每一行输出都要双重检查——这样做的结果是彻底扼杀了生产力。
我大量使用智能体工具,也惊叹于过去半年它们的进步有多大。但与此同时,我也常常被激怒——那么多大型任务发布的结果严重偏离常识和任务的本质精神。
最近,在阅读大量关于AI Agent的资料时,我特别关注人们指出的故障模式类型。很多时候,这些模式与我自己的体验高度吻合。当有人把一个模式提炼成模型或AI Agent的简短特征时,这简直是金子——就像"锯齿状"(jaggedness)这样的概念。这类知识能帮助你建立起关于AI Agent能力的直觉,以及围绕Agent合理组织工作的方式。它帮助你建立健康的期望,而不被那些过度销售的黑灯工厂和其他虚构的AI能力宣传所欺骗。
下面是我对这些故障模式的分类和梳理,它们来自几篇博客文章和会议演讲,与我的实际观察高度吻合。
故障模式一览
| 故障模式 | 一句话描述 | 来源 |
|---|---|---|
| 一次性吞下(One-shotting) | 试图一口吃掉整个应用,结果上下文耗尽,留下一个半成品烂摊子。 | Anthropic 长运行Agent |
| 进度即完成(Progress-as-completion) | 看到仓库里有活动,就把部分进度误认为整个任务已经完成。 | Anthropic 长运行Agent |
| 冷启动失忆(Cold-start amnesia) | 新会话既没有继承记忆也没有操作手册,结果浪费大量时间猜测之前发生了什么以及如何检查。 | Anthropic 长运行Agent |
| 丑陋的许愿(Ugly wish-granting) | 你表述得过于宽泛,Agent就按字面意思机械地执行——结果完整、彻底、且比你从未提出请求时还要丑陋。 | 作者观察 |
| 规格-交付物混淆(Spec-deliverable confusion) | 把临时的计划或设计文档当成实际交付物的一部分,把脚手架代码和真正要构建的东西打包在一起。 | 作者观察 |
| 默认填充垃圾(Default-fill slop) | 任务中未指定的部分被训练数据中的平庸默认值填充:样板代码、安全的UI布局、通用的产品选择。 | Mario Zechner |
| 默认过度工程(Overengineering by default) | 自动添加抽象层、重复代码、向后兼容和深度防御——因为互联网上的代码教会了它这些动作。 | Mario Zechner |
| 工作记忆衰减(Working-memory rot) | 重要事实虽然还在上下文中,但随着窗口增长,其可靠性逐渐下降。 | Random Labs Slate |
| 隐藏框架控制(Hidden harness control) | 工具在用户无法检查和操控的方式下,暗中改变上下文、提示、工具、提醒、可观测性和可扩展性。 | Mario Zechner |
| 有损压缩(Lossy compaction) | 压缩机制通过丢弃状态来维持长运行,但丢掉的恰恰可能是你需要的状态。 | Random Labs Slate |
| 局部修补(Local patching) | 每次调整在局部看起来都合理,但全局系统越来越难以推理。 | Mario Zechner |
| 仅摘要传递丢失(Summary-only handoff loss) | 子Agent隔离上下文后,只传回一份简洁的摘要,而不是足够安全的真实状态来保证集成。 | Random Labs Slate |
| 异步协调失败(Async reconciliation failure) | 并行工作带来了一个棘手的问题:什么时候结果是最终的?哪个分支胜出?什么才真正可组合? | Random Labs Slate |
| 盲N步执行(Blind N-step execution) | 委托出去的代码块在没有反馈的情况下运行太久,Agent只在最后才发现撞墙了。 | Random Labs Slate |
| 计划拖曳(Plan drag) | 计划和任务树阻止了提前终止——即使现实已经发生了变化,结构本身也在抵抗自适应调整。 | Random Labs Slate |
| 过度分解(Overdecomposition) | 规划者/实现者/审查者的堆栈虽然技术上可行,但增加了仪式感、延迟和惯性。 | Random Labs Slate |
| 验证中断(Validation interruption) | 在编辑过程中注入的诊断信息,在一个连贯的变更完成之前就把模型搞糊涂了。 | Mario Zechner |
| 虚假端到端完成(False E2E completion) | 单元测试通过了,curl命令也返回了200,但实际的用户路径仍然是坏的。 | Anthropic 长运行Agent |
| 功能正确但不对(Functional but wrong) | 结果通过了检查或勉强能用,但仍然笨拙、不可用、过度复杂,或者违背了任务的本质精神。 | 长视界Agent |
| 自我审查疲软(Self-review softness) | Agent给自己的平庸工作打了高分,自信地表扬,缺乏有力的批评。 | Anthropic 应用框架 |
| 模态盲区(Modality blind spots) | QA工具无法检测到它看不见、听不到或无法像真实用户一样操作的bug。 | Anthropic 应用框架 |
为什么这会变成疲劳
两个相关的问题不完全属于故障模式表,但它们解释了为什么整个过程会如此迅速地令人疲惫。
第一,生成速度超过了审查速度。Mario的"慢下来"不只是情绪宣泄,这是一个运营约束。一旦Agent可以比人类阅读的速度更快地生成代码、测试、Issue和PR,瓶颈就从打字转移到了判断。
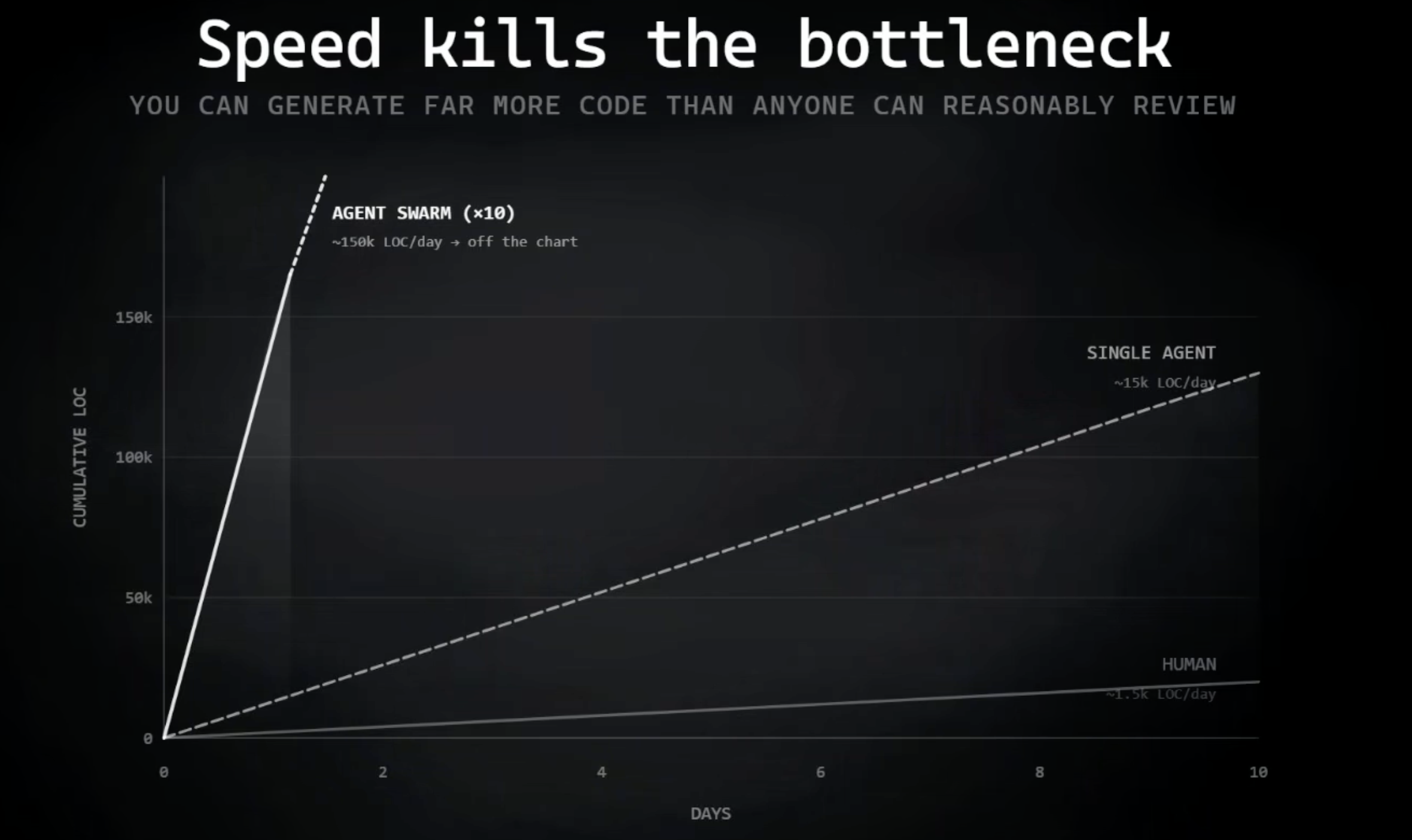
第二,同样的动态也泄漏到你的仓库之外。AI生成的Issue、AI生成的PR、合成的评论、自动生成的文档、泛泛的帖子——其中一些可能有价值,但渠道被看似合理的文本填满的速度远远超过了人们筛选的速度。认知残留物是疲劳、犬儒主义、AI脑腐,最终变成全大写的提示词,乞求机器别再耍小聪明,老老实实把活干了。
修复方案及其副作用
| 修复方案 | 解决的故障 | 破坏/产生的问题 |
|---|---|---|
| 上下文重置(Context reset) | 长任务漂移、上下文焦虑 | 交接产物成为关键状态。糟糕的交接意味着糟糕的下一轮会话。 |
| 压缩(Compaction) | 保持长运行持续 | 不可预测地丢失重要状态。 |
| 功能列表/任务列表 | 一次性吞下、过早完成 | 僵化的计划、过时的状态、打勾表演。 |
| 严格任务树 | 提前终止、不完整分解 | 表达力低;现实变化时难以适配。 |
| 子Agent(Subagents) | 上下文隔离、并行搜索 | 薄摘要、消息传递限制、合并问题。 |
| 独立评估器 | 自我赞美和薄弱审查 | 评估器仍然会遗漏问题;标准本身也会产生符合评分标准的垃圾。 |
| 浏览器/端到端测试 | 局部检查导致的虚假完成 | 工具盲区仍然存在;感知限制仍然存在。 |
| 用户自有的极简框架 | 隐藏的供应商行为、不透明性、浅层可扩展性 | 安全、工作流设计和维护的责任回到用户身上。 |
参考来源
- Anthropic, "Effective harnesses for long-running agents", 2025年11月
- Anthropic, "Harness design for long-running application development", 2026年3月
- Random Labs, "Slate: moving beyond ReAct and RLM", 2026年3月
- Mario Zechner, "Building Pi in a World of Slop", AI Engineer大会演讲, 2026年4月
原文:AI Agent Failure Modes Beyond Hallucination(作者:Maxim Saplin)
——
zhirenhun
一个热爱技术的程序员,喜欢分享前沿AI知识和开发经验。


