DuckDB 内部原理:为什么 DuckDB 这么快?(上篇)
从 2019 年荷兰 CWI 的研究项目起步,DuckDB 已经成长为过去十年中采用最广泛的数据库之一。它的身影出现在各个角落:Jupyter Notebook、ETL 管道、数据仪表盘、CI 测试运行器、SaaS 产品中的嵌入式分析,甚至有人把 DuckDB 放进干冰盒子里,在 iPhone 上跑 TPC-H 基准测试。
围绕它已经形成了一套完整的生态系统。MotherDuck 把 DuckDB 包装成了云数据仓库;Hex、Omni、Evidence 等 BI 平台用它作为应用内执行引擎和缓存层;Fivetran 的托管数据湖服务在数据湖写入器中用 DuckDB 做合并和压缩;Rill 在其开源 BI 工具上构建。
DuckDB 的核心定位:进程内分析数据库
DuckDB 是一个"进程内分析 SQL 数据库"——这意味着两件事。第一,它是为分析型查询优化的。这类查询需要扫描数百万行来做过滤、聚合和连接,而不是按主键查单条记录。第二,它没有服务器。你不需要连接到 DuckDB,而是像加载 NumPy 或 Polars 一样,把它作为库加载到你的程序中。
DuckDB 之所以被广泛采用,很大程度上是因为它太好用了。它只发行一个不到 20MB 的单一二进制文件,没有任何外部依赖,可以用一行 pip install 安装。
本文是 DuckDB 内部原理三篇深度解析的第一篇。DuckDB 的速度来自列式压缩存储配合区域映射、Morsel 驱动的并行机制、快照隔离与乐观 MVCC。
进程内架构:避开序列化的性能陷阱
大多数分析数据库都是服务器模式的:Snowflake、PostgreSQL、BigQuery、Redshift。你建立连接,通过 TCP 发送 SQL,等待结果返回。在这个过程中,结果集中的每条记录都要被序列化为有线协议格式、通过网络传输、再在客户端反序列化回本地类型。
DuckDB 不是服务器。它是库。没有 DuckDB 守护进程,没有端口,没有集群。你把 DuckDB 加载到程序中,直接调用函数查询数据。
2017 年的论文 "Don't Hold My Data Hostage" 测量了从数据仓库拉取结果集时的实际开销,发现客户端协议本身——ODBC、JDBC——往往是整个查询中最慢的环节。DuckDB 通过和客户端运行在同一个进程中来避开这两个瓶颈。
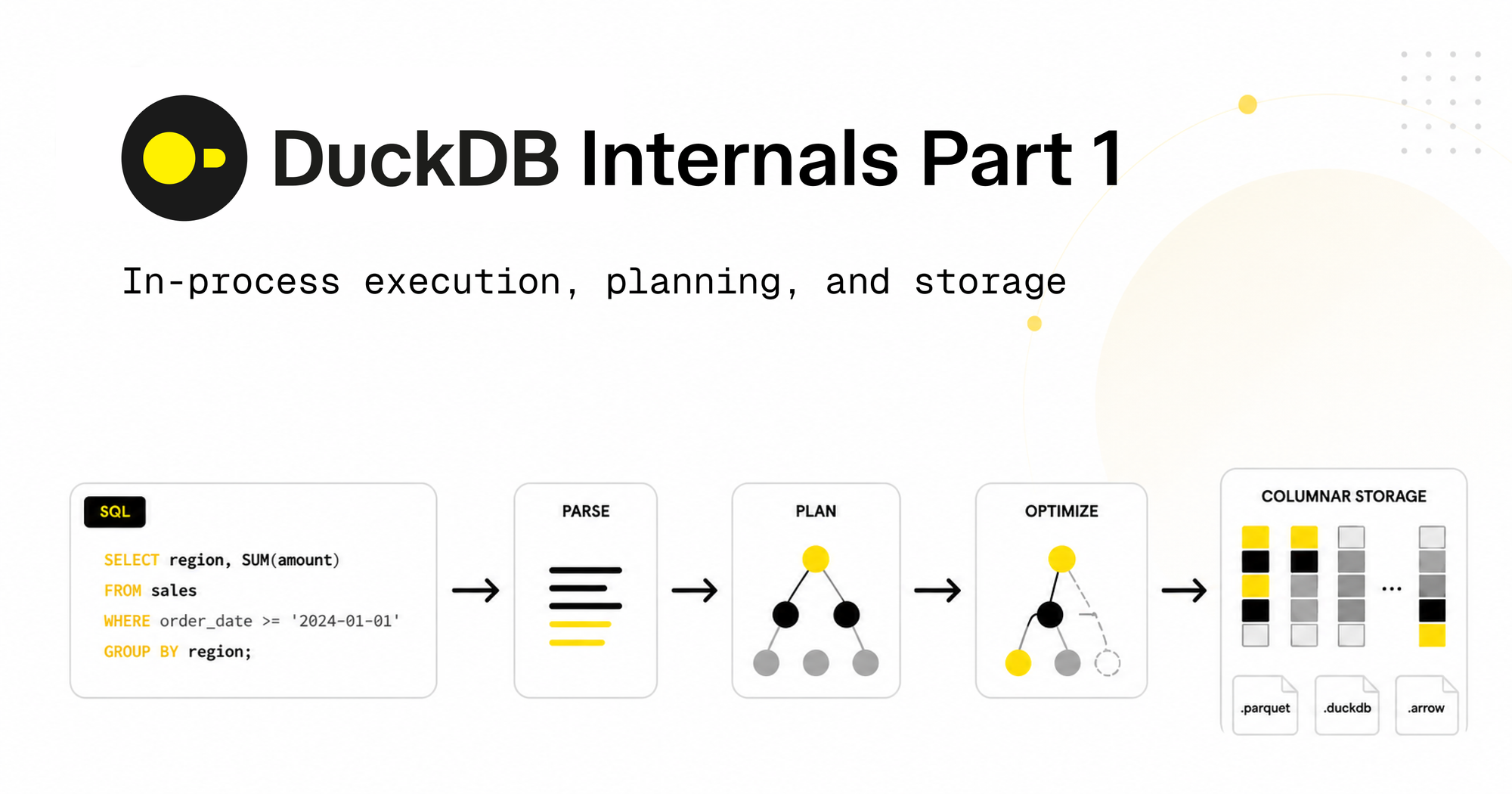
从 SQL 到逻辑计划
DuckDB 的查询处理分几个阶段:解析 SQL 为 AST、绑定到目录、优化、生成物理计划。优化器由一系列小而专注的变换组成,包括谓词下推、子查询解嵌套、动态连接过滤下推和连接顺序优化。整个优化阶段通常在大约一毫秒内完成。
物理计划与流水线
DuckDB 不会将物理计划作为一次巨大的树遍历来运行。它把计划分解为流水线(Pipeline),每个 CPU 核心可以运行自己的装配线副本。有些操作符(排序、聚合、哈希连接构建端)需要看到完整输入才能产生输出,这些被称为 Sink(汇)。
列式存储与区域映射
DuckDB 的数据库是一个单一文件,受 SQLite 启发。文件内部数据被分成固定大小的块(默认 256KB),每列分开存储,每列被分成行组(最多 122,880 行)。每个行组带有区域映射,包含最小值、最大值和空值计数。当查询带有过滤条件时,DuckDB 在读取任何数据之前先检查行组的最大值,不满足条件的行组被完全跳过。
下一篇将深入向量化执行引擎、Morsel 驱动的并行机制以及 MVCC 的实现细节。