文本嵌入能完美编码文本吗?——Vec2text的反向重建与安全警示
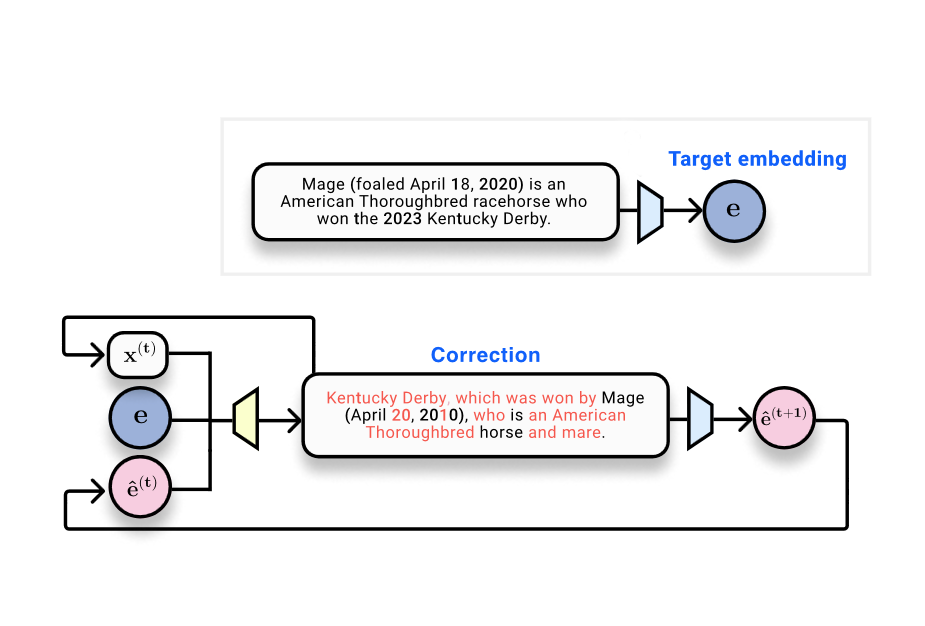
文本嵌入(text embeddings)作为NLP系统的基石,广泛应用于语义搜索、聚类、检索增强生成(RAG)等任务。这些嵌入向量将自然语言压缩为高维稠密表示,通常被视为一种“抽象”形式——丢失了原始句子的精确词汇顺序,仅保留语义特征。然而,The Gradient的这篇文章揭示了一个颠覆性事实:通过一种名为Vec2text的模型,嵌入向量可以被近乎完美地还原为原始文本,这直接动摇了当前对“嵌入即匿名”的安全假设。
Vec2text的核心思路非常直观:训练一个神经网络从嵌入向量反推其对应的文本。具体而言,它采用编码器-解码器结构,首先将给定的嵌入向量作为输入,然后通过一个类似T5或BART的序列生成模型逐步重建文本。关键在于,训练时所用的嵌入向量由预训练模型(如Sentence-BERT、OpenAI的text-embedding-ada-002等)生成,因此Vec2text学习的是该特定嵌入函数的逆映射。实验结果表明,对于短文本(例如单句话),重建的准确率极高——BLEU和ROUGE得分接近完美,甚至能还原出拼写错误和特殊符号。
这一发现带来了严峻的安全隐患。许多系统会将用户输入的文本嵌入存储到数据库中(如用于检索或分析),并声称嵌入已经“脱敏”,因为无法直接从向量读取原始信息。但Vec2text证明,只要攻击者掌握了嵌入模型的具体参数或黑盒API接口,并通过构造大量(嵌入,文本)对进行训练,就能有效恢复隐私文本。例如,医疗记录、对话历史、个人邮件等敏感信息,一旦嵌入向量泄露,便可能被反推还原。
文章进一步指出,目前尚缺乏嵌入级别的强加密标准。一种对策是将嵌入向量视为“代理数据”,对存储和传输过程施加与原始文本相同的安全等级(如差分隐私、同态加密)。另一种思路是设计更“不可逆”的嵌入模型——故意在编码过程中引入信息损失,使得重建变得不精确。但这样做又会降低下游任务的效果,形成性能与隐私之间的权衡。
Vec2text的出现是一个及时的警醒:在AI应用中,数据安全的边界远比我们想象的更模糊。任何对输入信息的“抽象”都应被谨慎对待,尤其是在涉及用户隐私的领域。未来的安全协议需前瞻性地将嵌入纳入保护范围,而不是等到大规模泄露事件发生后才亡羊补牢。
——
zhirenhun
一个热爱技术的程序员,喜欢分享前沿AI知识和开发经验。


