自适应并行推理(APR):高效推理扩展的下一个范式
概述
如果一个推理模型能够自行决定何时分解和并行化独立子任务、需要产生多少个并发线程、以及如何根据当前问题协调它们——那会怎样?本文对并行推理领域的最新进展,特别是自适应并行推理(Adaptive Parallel Reasoning, APR),进行了详细分析。
声明:本文兼有领域综述和自适应并行推理视角分析。其中一位作者(Tony Lian)共同领导了 ThreadWeaver(Lian et al., 2025),这是下文讨论的方法之一。作者力求客观呈现每种方法。
动机
LLM 推理能力的最新进展,除了数据和参数规模扩展外,很大程度上得益于推理时计算扩展(inference-time scaling)(OpenAI et al., 2024; DeepSeek-AI et al., 2025)。那些显式输出推理 token(通过中间步骤、回溯和探索)的模型,如今在数学、编程和智能体基准测试中占据主导地位。这些行为使模型能够探索替代假设、纠正早期错误并综合结论,而非只承诺一个单一解决方案(Wen et al., 2025)。
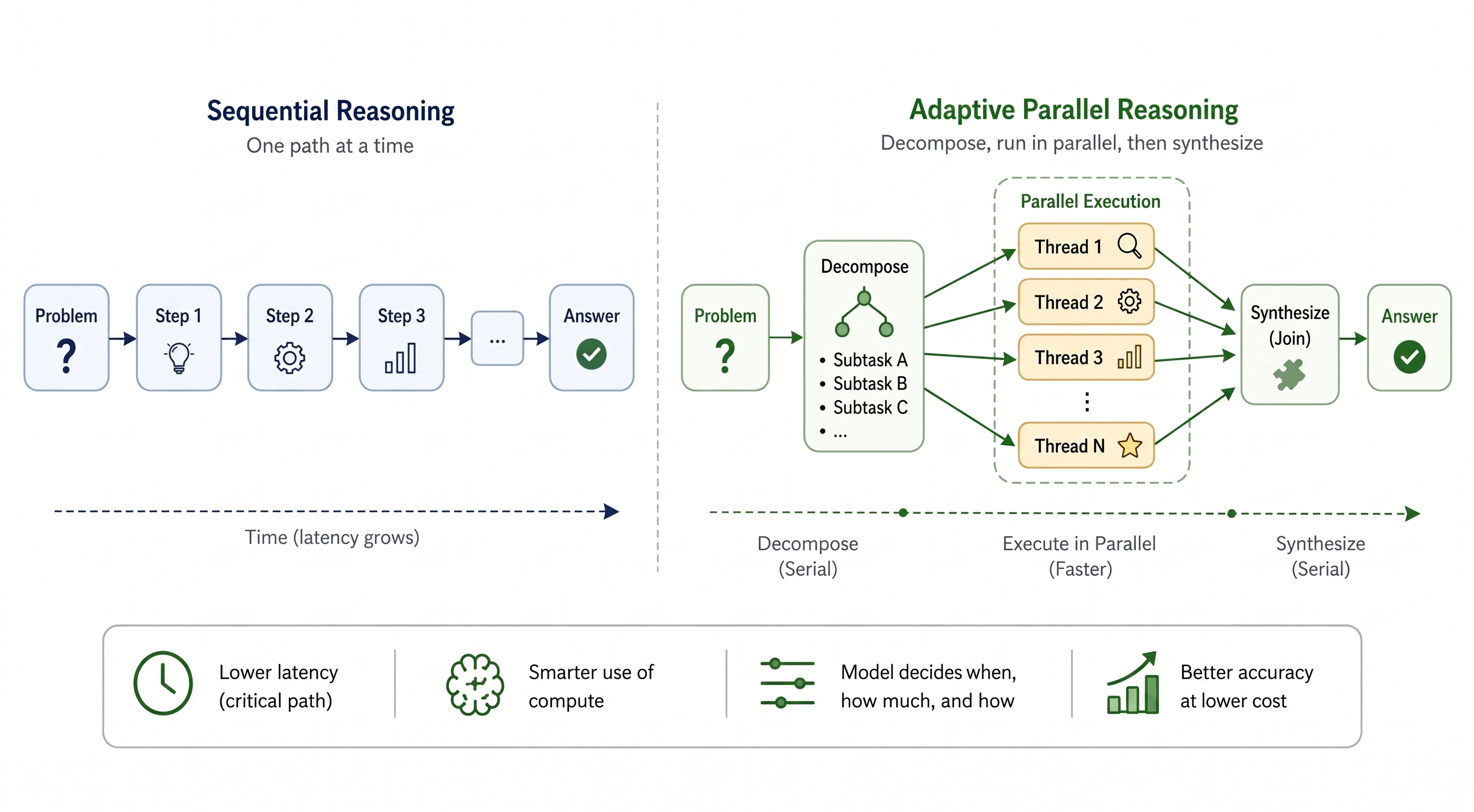
问题在于,顺序推理的计算量随探索量线性增长。扩展顺序推理 token 是有代价的——模型可能超出有效的上下文窗口限制(Hsieh et al., 2024)。中间探索路径的累积使模型在注意力机制中难以从干扰项中区分有效信息,导致性能下降,这种现象被称为 上下文腐烂(context-rot)(Hong, Troynikov and Huber, 2025)。延迟也随推理长度成比例增加。对于需要数百万 token 进行探索和规划的复杂任务,用户等待数十分钟甚至数小时才得到答案的情况并不少见(Qu et al., 2025)。随着我们沿着输出序列长度方向继续扩展,推理变得越慢、越不可靠、计算成本越高。并行推理因此成为一种自然的解决方案。与其顺序探索路径(Gandhi et al., 2024)并在每一步都累积上下文窗口,我们可以让模型独立(线程间不依赖彼此上下文)且并发(线程可同时执行)地探索多个线程。
近年来,越来越多的研究工作在合成场景(如倒计时游戏 Countdown, Katz, Kokel and Sreedharan, 2025)、真实数学问题和通用推理任务中探索了这一思路。
从固定并行到自适应控制
现有方法表明并行推理确实有帮助,但它们大多数仍然在模型外部决定并行结构,而不是让模型自己选择。
简单的分支-合并(Fork-and-Join)。
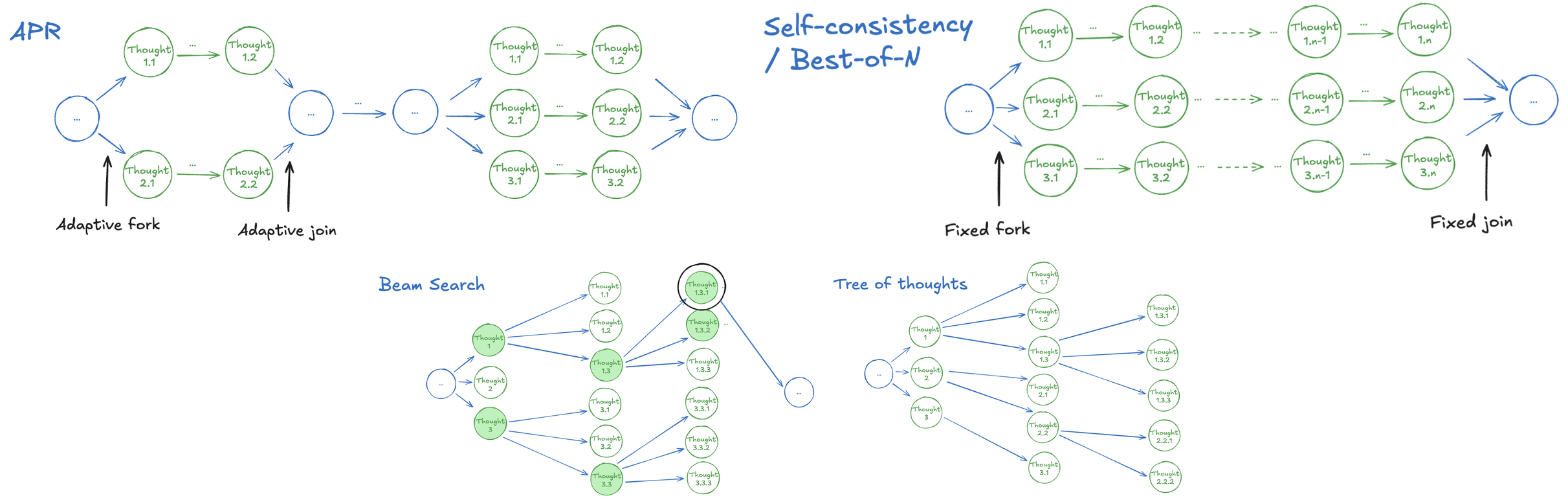
- 自一致性/多数投票(Self-consistency/Majority Voting)——独立采样多个完整的推理轨迹,从每条轨迹提取最终答案,返回出现最多的那个(Wang et al., 2023)。
- Best-of-N(BoN)——与自一致性类似,但使用训练好的验证器来选择最佳解决方案,而非多数投票(Stiennon et al., 2022)。
- 虽然实现简单,但这些方法在不同分支间常产生冗余计算,因为轨迹是独立采样的。
基于启发式的结构化搜索。
- 思维树/图/骨架(Tree / Graph / Skeleton of Thoughts)——一系列结构化分解方法,使用已知搜索算法(BFS/DFS)探索多个替代"思维",并通过基于 LLM 的评估进行剪枝(Yao et al., 2023; Besta et al., 2024; Ning et al., 2024)。
- 蒙特卡洛树搜索(MCTS)——通过随机 rollout 估计节点值,并使用上置信界(UCB)风格的探索-利用平衡来扩展搜索树(Xie et al., 2024; Zhang et al., 2024)。
- 这些方法通过将任务分解为不重叠的子任务改进了简单的分支-合并;然而,它们需要预先了解分解策略,而这并不总是已知的。
近期变体。
- ParaThinker——训练模型以两个固定阶段运行:首先生成多个并行推理线程,然后综合它们。他们引入了可训练的控制 token(
<think_i>)和思维特定的位置编码,通过两阶段注意力掩码在推理期间强制独立性,在总结阶段实现受控整合(Wen et al., 2025)。 - GroupThink——多个并行推理线程可以在 token 级别看到彼此的局部进展,并在生成过程中自适应调整。与之前基于独立请求的并发方法不同,GroupThink 让单个 LLM 同时产生多个相互依赖的推理轨迹(Hsu et al., 2025)。
- Hogwild! Inference——多个并行推理线程共享 KV 缓存,并在没有显式协调协议的情况下决定如何分解任务。工作线程并发地向共享注意力缓存生成内容,使用 RoPE 以不同顺序拼接各个 KV 块而无需重计算(Rodionov et al., 2025)。
上述方法有一个共同的局限性:是否并行化、并行化程度和搜索策略都是强加给模型的,不管问题本身是否真正受益于此。然而,不同的问题需要不同级别的并行化,这对并行化的有效性至关重要。例如,一个对"25+42等于多少?"和"在哪个最小平面区域内可以连续旋转一条单位长度的线段180°?"应用相同并行结构的框架,前者浪费算力,后者可能使用了错误的分解策略。在上述方法中,模型并没有学会这种自适应行为。一个自然的问题随之产生:如果模型能自行决定何时并行化、产生多少个线程、以及如何根据当前问题协调它们——那会怎样?
自适应并行推理(Adaptive Parallel Reasoning, APR)通过将并行化作为模型生成控制流的一部分来回答这个问题。从形式上讲,自适应性指的是模型在推理时动态地在并行和串行操作之间分配计算资源的能力。换句话说,具有自适应并行推理能力的模型学会了协调其控制流——即何时顺序生成序列,何时并行生成。
值得注意的是,自适应并行推理的概念由论文《Learning Adaptive Parallel Reasoning with Language Models》(Pan et al., 2025)提出,但它是一个范式(paradigm)而非特定方法。在本文中,APR 指代该范式,而"APR 方法"特指 Pan et al.(2025)的具体实现。
这一转变的重要性体现在三个方面。与思维树相比,APR 不需要领域特定的分解启发式。在强化学习过程中,模型通过试错学习通用的分解策略。事实上,模型会以涌现的方式发现有用的并行化模式——比如将下一步的执行与前一步的自我验证并行进行,或者用一个备选方案对冲主要方案——这些模式很难通过人工设计实现(Yao et al., 2023; Wu et al., 2025; Zheng et al., 2025)。
与 BoN 相比,APR 避免了冗余计算。APR 模型在分支之前能控制每个并行线程将要做什么。因此,APR 可以学习在将子任务分配给独立线程之前,产生一组独特的、不重叠的子任务(Wang et al., 2023; Stiennon et al., 2022; Pan et al., 2025; Yang et al., 2025)。
与非自适应方法相比,APR 可以选择不并行化。自适应模型可以根据问题的复杂度与并行化的开销来调整并行化程度(Lian et al., 2025)。
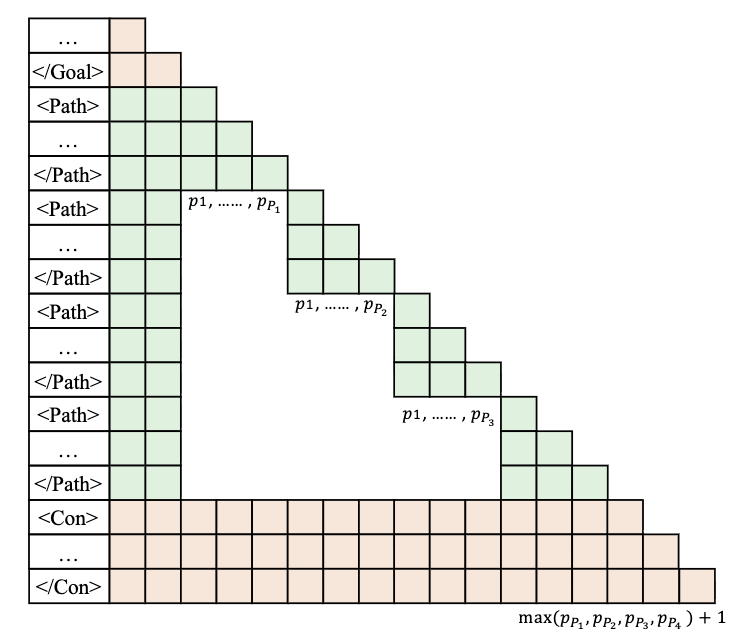
在实践中,这是通过让模型输出特殊 token 来控制何时并行推理、何时顺序推理来实现的。以下是 ThreadWeaver 风格的浓缩轨迹示例:在 <Parallel> 块下有两个大纲和两条路径,然后线程在单个框定答案上达成一致。

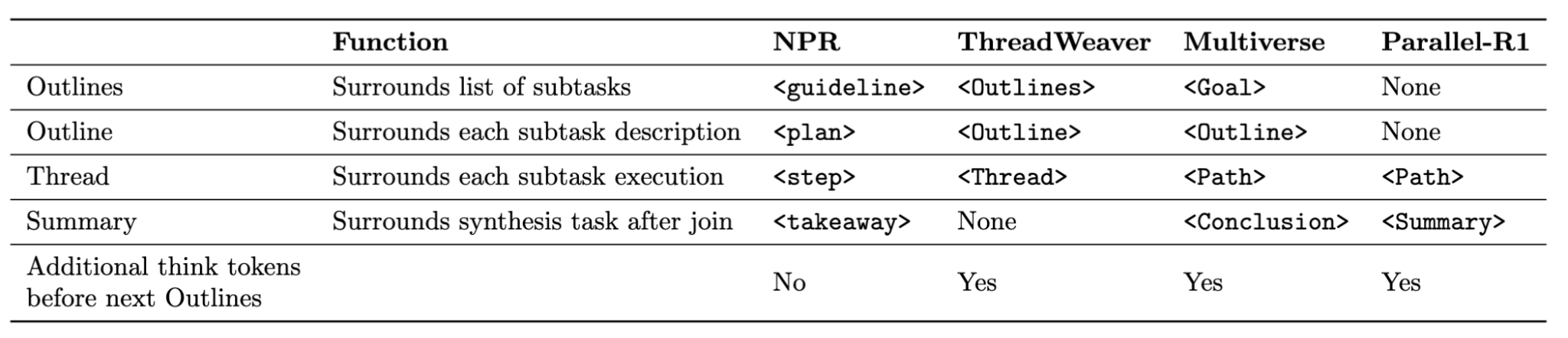
自适应并行化的推理系统
那么我们实际上如何执行并行分支呢?我们从计算机系统中汲取灵感,特别是多线程和多进程。大部分工作都可以看作利用了分支-合并(fork-join)设计。
在推理时,我们实际是在让模型执行一个 Map-Reduce 操作:
- 将问题分支(Fork)为子任务/线程,并发处理它们
- 然后将它们合并(Join)为最终答案
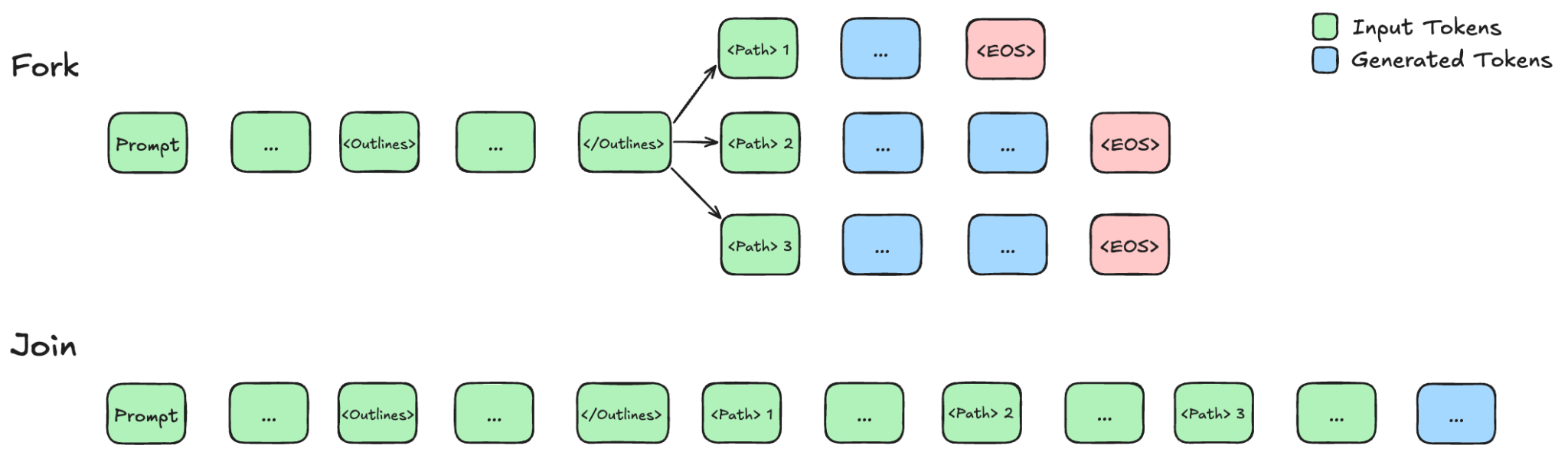
具体来说,模型会遇到一组子任务。它会为每个子任务进行预填充(prefill),然后将它们作为独立的请求发送给推理引擎处理。这些线程随后并发解码,直到遇到结束 token 或超出最大长度。这个过程会阻塞直到所有线程完成解码,然后聚合结果。这在各种自适应并行推理方法中都很常见。然而,聚合阶段出现了一个问题:分支中生成的内容无法在 KV 缓存层面轻松聚合。这是因为独立线程中的 token 从相同的位置 ID 开始,导致编码重叠,在合并 KV 缓存时产生非标准行为。同样,由于独立线程不互相注意,它们拼接后的 KV 缓存会产生非因果注意力模式,而基础模型在训练期间从未见过这种模式。
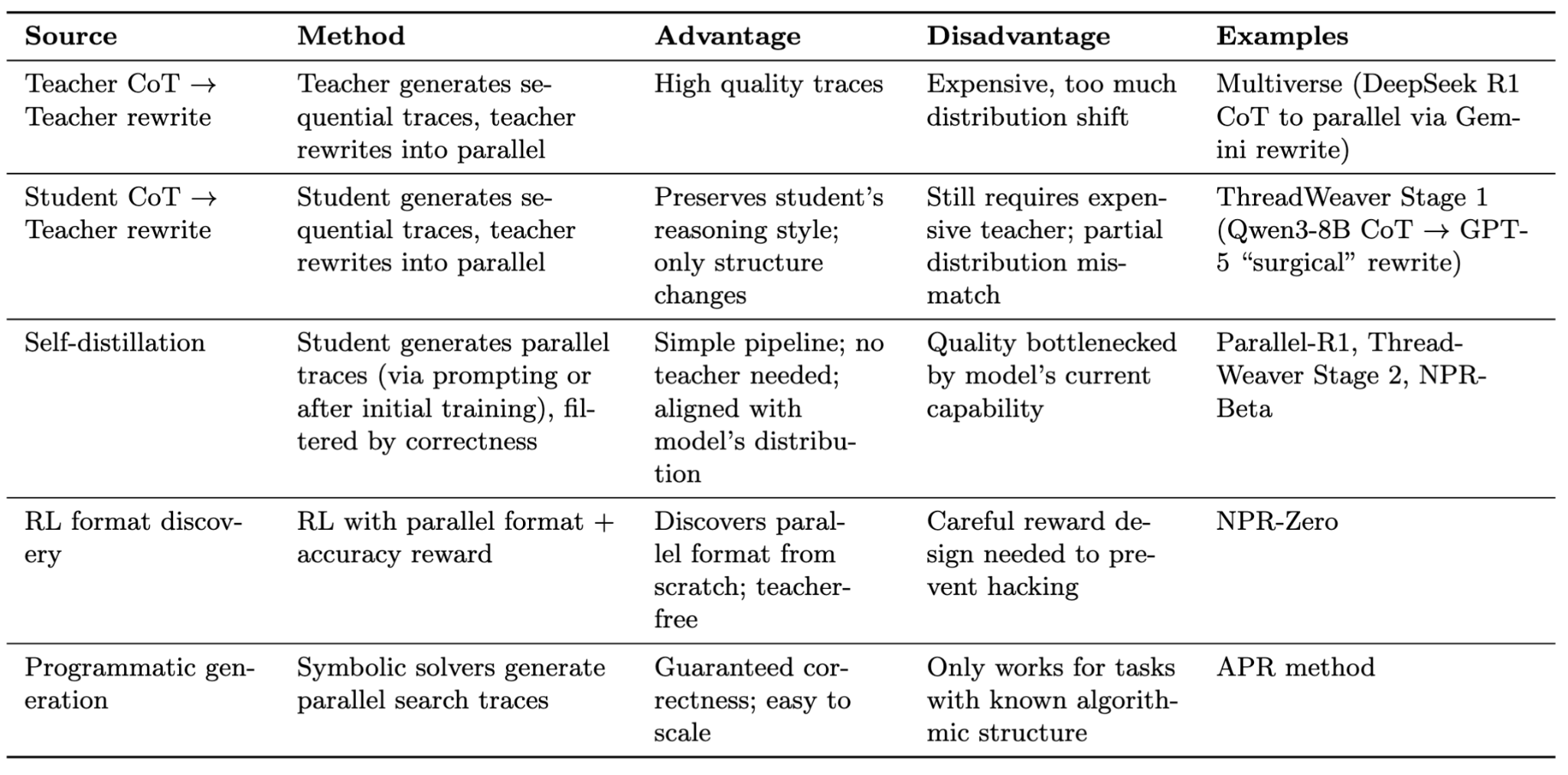
为了解决这个问题,该领域分为两种思路,区别在于是否修改推理引擎。
Multiverse 修改推理引擎以在合并阶段重用 KV 缓存。在深入了解 Multiverse(Yang et al., 2025)的内存管理之前,我们先理解 KV 缓存一直到"合并"阶段是如何处理的。注意每个独立线程都共享前缀序列,即子任务列表。如果不加优化,每个线程都需要为前缀序列进行预填充并重新计算 KV 缓存。然而,这种冗余可以通过 SGLang 的 RadixAttention(Sheng et al., 2023)来避免,它将多个请求组织成基数树(radix tree)——一种前缀树(trie),其中节点包含可变长度的元素序列而非单个元素。这样,唯一的新的 KV 缓存条目来自独立线程的内容生成。
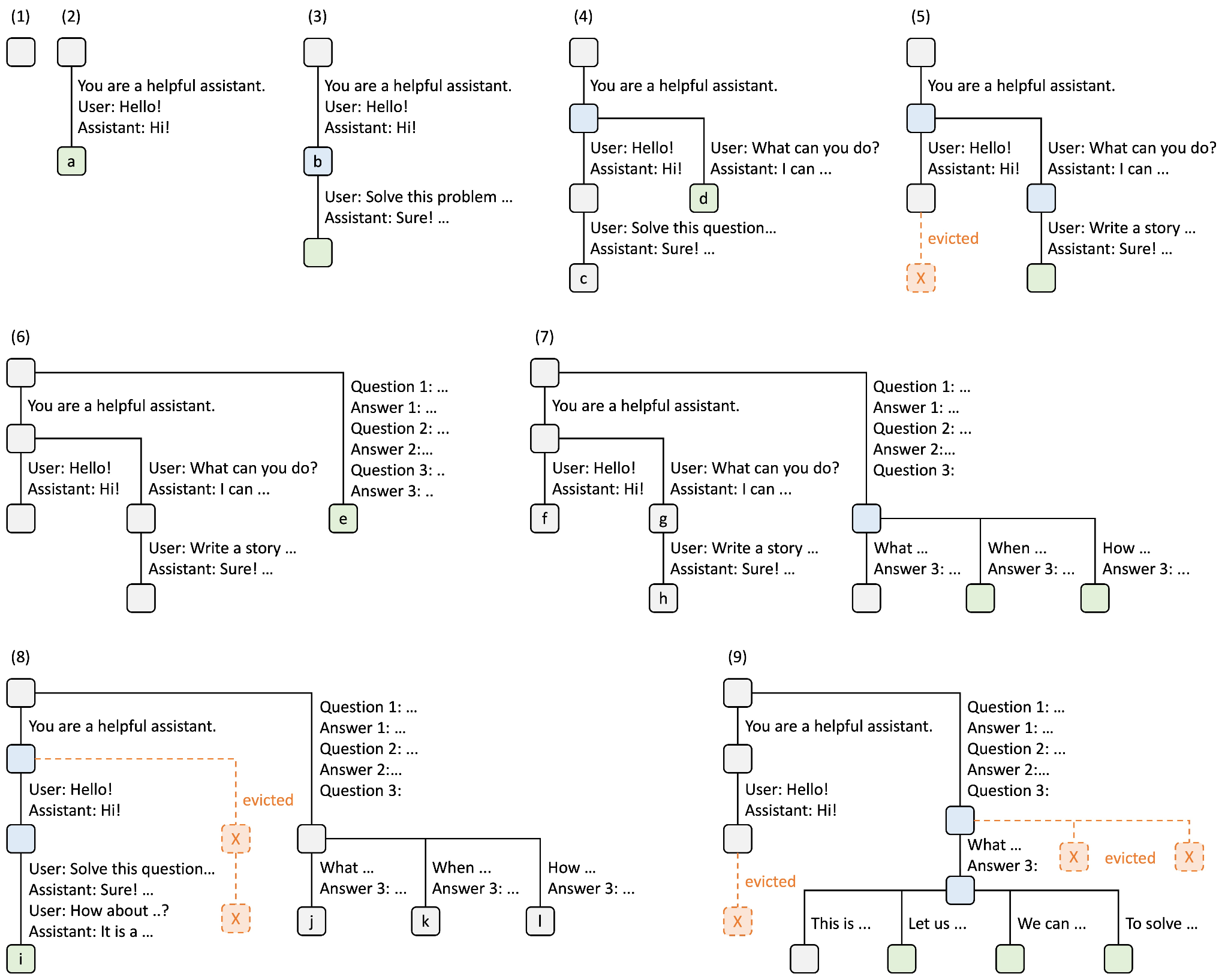
现在,如果一切顺利,所有独立线程都已从推理引擎返回。我们的目标是找出如何将它们综合回单个序列,以便继续为下一步解码。事实证明,我们可以在综合阶段重用这些独立线程的 KV 缓存。具体来说,Multiverse(Yang et al., 2025)、Parallel-R1(Zheng et al., 2025)和 NPR(Wu et al., 2025)修改了推理引擎,将每个线程生成的 KV 缓存复制过来,并编辑页表,将非连续的内存块拼接成单个 KV 缓存序列。这避免了第二次预填充的冗余计算,并尽可能重用现有 KV 缓存。然而,这种方法有若干主要限制。
首先,这种方法需要修改推理引擎以执行非标准的内存操作,可能导致意外行为。具体来说,由于综合请求引用了之前请求的 KV 缓存,系统变得脆弱,可能出现坏指针。另一个请求可能在综合请求完成之前到来并驱逐被引用的 KV 缓存,迫使其暂停并触发重新预填充之前的线程请求。这个问题导致 Multiverse 的研究人员(Yang et al., 2025)限制了推理引擎可处理的批处理大小,从而限制了吞吐量。
其次,这种方法改变了模型看待序列的方式,产生了分布偏移——模型在预训练时从未见过这种行为,因此需要更广泛的训练来对齐行为。具体来说,当我们这样拼接 KV 缓存时,创建了一个具有非标准位置编码的序列。在独立线程生成期间,所有线程从相同的位置索引开始,注意之前的子任务而不是彼此。因此,当线程合并回来时,产生的 KV 缓存具有非标准的位置编码,并且不使用因果注意力。因此,这种方法需要大量训练来使模型适应这种新行为。为了解决这个问题,Multiverse(Yang et al., 2025)及相关工作在训练期间应用修改后的注意力掩码,防止独立线程互相注意,从而使训练和推理行为对齐。
鉴于非标准 KV 缓存管理带来的这些问题,我们能否尝试一种无需修改引擎的方法?
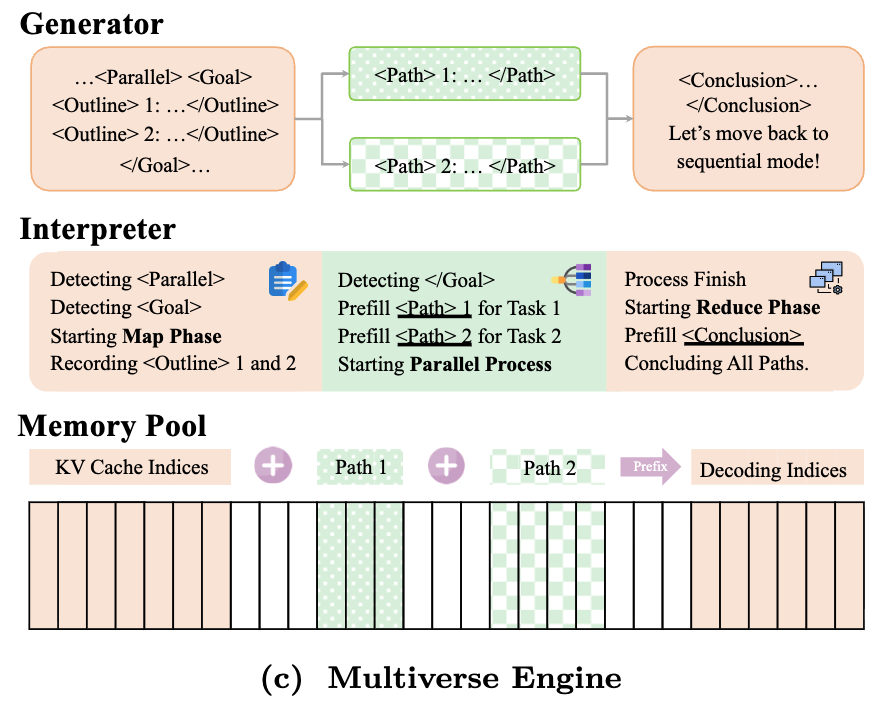
ThreadWeaver 保持推理引擎不变,将编排移至客户端。ThreadWeaver(Lian et al., 2025)将并行推理纯粹视为客户端问题。"分支"过程与 Multiverse 几乎相同,但合并阶段处理内存的方式截然不同——它不修改引擎内部。相反,客户端将所有独立分支的文本输出拼接成单个连续序列。然后,引擎执行第二次预填充,为结论生成步骤生成 KV 缓存。虽然这引入了 Multiverse 试图避免的计算冗余,但预填充的成本远低于解码。此外,这不需要推理期间的特殊注意力处理,因为第二次预填充使用因果注意力(线程彼此可见),使得适配顺序自回归模型来完成此任务更加容易。
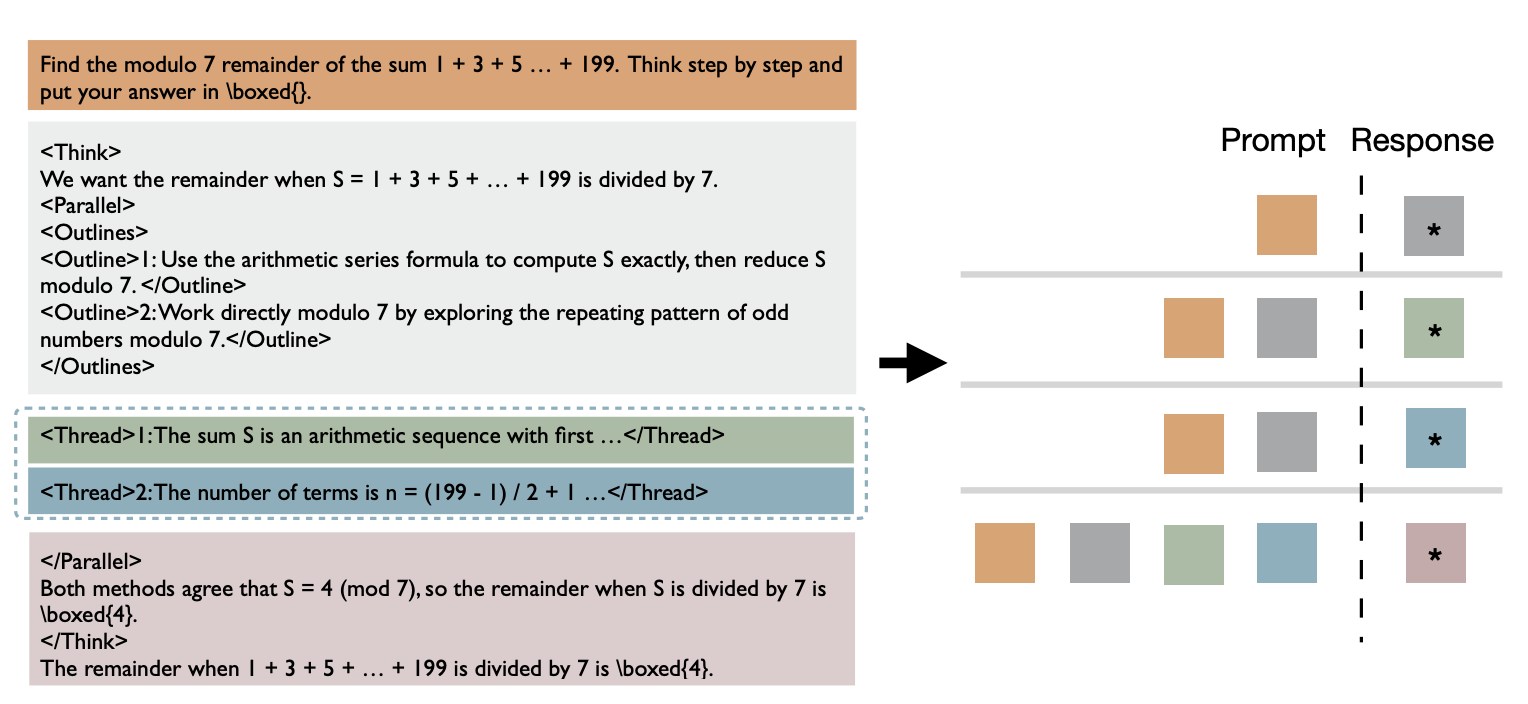
我们如何训练模型学习这种行为呢?朴素的方法是,对于每条并行轨迹,我们可以按照推理模式将其分解为多个顺序片段。例如,我们会训练模型根据提示输出子任务,根据提示+子任务分配输出独立线程,以及根据提示+子任务+对应线程输出结论。然而,这看起来很冗余且计算效率不高。我们能做得更好吗?事实证明,是的。正如 ThreadWeaver(Lian et al., 2025)中所示,我们可以将并行轨迹组织成前缀树(trie),将其展平为单个序列,并在训练期间(注意:非推理期间)应用仅祖先注意力的掩码。
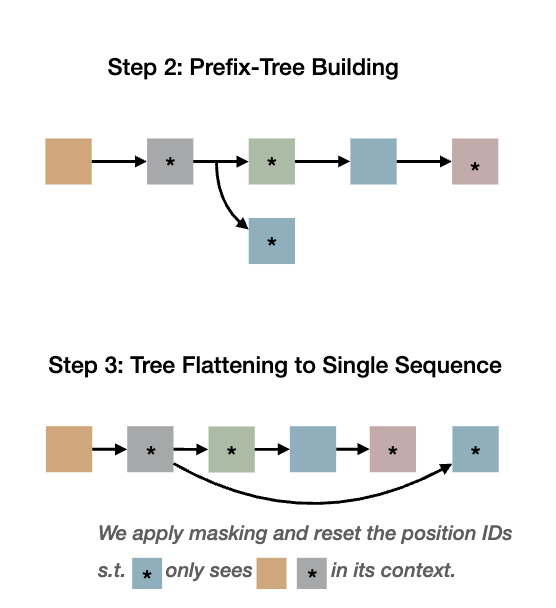
具体来说,我们应用掩码和位置 ID 来模拟推理行为,使得每个线程仅以提示+子任务为条件,而从不关注兄弟线程或最终结论。
这种引擎无关的设计使部署变得容易——你不需要搞定单独的托管方案,可以直接利用现有的硬件基础设施。它还会随着推理引擎的改进而变得更好。此外,使用引擎无关的方法,我们可以轻松地提供一个在顺序和并行思维模式之间切换的混合模型。
训练模型使用并行化
有了推理路径之后,下一个问题是如何教会模型使用它。需要示范数据(demonstrations)因为模型必须学会输出编排控制流的特殊 token。我们发现基础模型的指令遵循能力不足以生成并行线程。
这里一个有趣的问题是:SFT 训练是赋予模型以前缺失的并行执行推理能力,还是仅仅将模型已有的预训练能力对齐到特定的控制流 token 语法?传统观点认为 SFT 教授新知识;但与普遍认知相反,一些论文——特别是 Parallel-R1(Zheng et al., 2025)和 NPR(Wu et al., 2025)——认为它们的 SFT 示范只是诱导了格式遵循(即如何构建并行请求)。我们将此问题留给未来研究。
示范数据教会了并行控制流的语法,但没有完全解决激励问题。在理想情况下,我们只需要奖励结果的准确性,并行化模式就会自然涌现——假设模型通过 SFT 学会了输出特殊 token,类似于长思维链(long CoT)的涌现。然而,研究人员(Zheng et al., 2025)发现这还不够,我们确实需要并行化激励。问题就变成了:我们如何判断模型是否在有效并行化?
仅结构奖励太容易被钻空子。朴素的做法是对产生的线程数量给予奖励。但模型可以产生许多简短而无用的线程来骗取奖励。好吧,这行不通。那么,对正确使用并行结构给予二元奖励呢?这部分解决了模型滥用新线程的问题,但模型仍然会在不需要时也产生线程。Parallel-R1(Zheng et al., 2025)的作者引入了交替调度策略,仅在 20% 的时间奖励并行结构,这成功地将并行结构的使用率从 13.6% 提升至 63%,但对整体准确率影响不大。
采用这种仅结构奖励的方法,我们可能正在偏离最初提高准确率和降低延迟的目标……我们如何直接优化帕累托前沿?准确率很简单——我们只需查看结果。那延迟呢?
效率奖励需要追踪关键路径(Critical Path)。在纯顺序轨迹中,我们可以根据生成的 token 总数来衡量延迟。为了将其扩展到并行轨迹,我们可以关注关键路径——即因果依赖的最长 token 序列——因为它直接决定了我们的端到端生成时间(即墙钟时间)。例如,当有两个 <Parallel> 部分各有五个线程时,关键路径将穿过第一个并行部分中最长的线程,然后是任何顺序 token,然后是第二个并行部分中最长的线程,以此类推直到序列结束。

目标是尽量缩短关键路径的长度。同时,我们仍然希望模型花费 token 并行探索线程。为了结合这两个目标,我们可以专注于让关键路径占总 token 消费量的更小比例。ThreadWeaver(Lian et al., 2025)的作者将并行化奖励设定为 $1 - L_{mathrm{critical}} / L_{mathrm{total}}$,这在顺序轨迹中为 0,随着关键路径相对于总生成 token 的减小而线性增加。
并行效率应以保证正确性为前提。直观上,当多条轨迹都正确时,我们应该给并行化效率更高的轨迹更多奖励。但如果它们都错了呢?我们是否应该给予任何奖励?可能不应该。
形式上,$R = R_{mathrm{correctness}} + R_{mathrm{parallel}}$。假设二元结果正确性,可以写作 $R = mathbf{1}( ext{Correctness}) + mathbf{1}( ext{Correctness}) imes ( ext{某个并行化指标})$。这样,模型只有在答案正确时才获得并行化奖励——因为如果模型不能正确回答问题,我们就不想对其施加并行化约束。

评估与开放问题
归根结底,这些自适应并行方法的实际表现如何?嗯……这是一个很难回答的问题,因为它们在模型选择和评估指标上各不相同。模型的选择取决于训练方法、SFT 问题的难度和序列长度。当在 s1k 等困难数据集上运行 SFT 时——其中包含研究生级别的数学和科学问题——研究人员选择了大型基础模型(Multiverse 使用 Qwen2.5 32B, Yang et al., 2025)来捕捉解决方案轨迹背后的复杂推理结构。当运行强化学习时,由于计算成本限制,研究人员选择了小型非 CoT 指令模型(4B, 8B)。
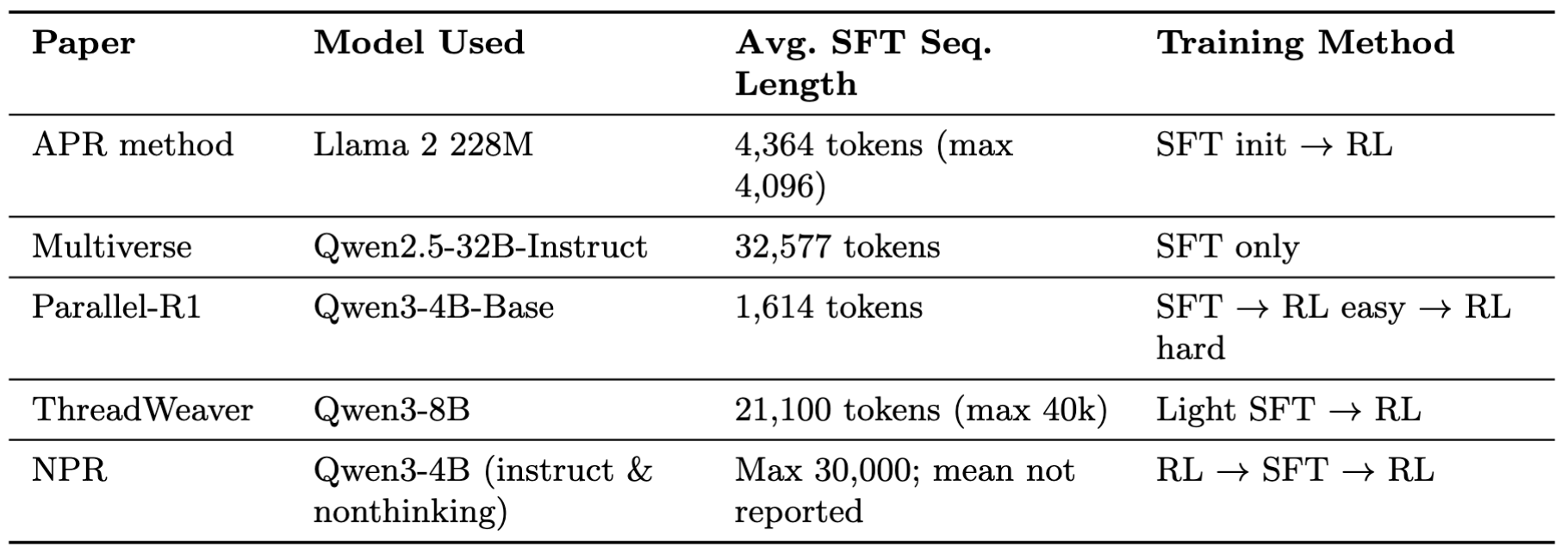
每篇论文对自适应并行推理如何贡献于该研究领域也有略微不同的解释。它们优化不同的理论目标,因此使用略有不同的指标集:
- Multiverse 和 ThreadWeaver(Yang et al., 2025; Lian et al., 2025)旨在以更快的速度达到顺序自回归模型水平的准确率。Multiverse 展示了 APR 模型在相同的固定上下文窗口下可以达到更高的准确率,而 ThreadWeaver 展示了 APR 模型在保持相当准确率的同时实现了更短的端到端 token 延迟(关键路径长度)。
- NPR(Wu et al., 2025)将顺序回退视为失败模式,优化 100% 的纯并行化率(Genuine Parallelism Rate),即并行 token 与总 token 的比率。
- Parallel-R1(Zheng et al., 2025)不关注端到端延迟,而是优化探索多样性,将 APR 呈现为一种在 RL 后提供性能提升的中期训练探索框架。
开放问题
虽然自适应并行推理代表了迈向更高效推理时计算扩展的有希望的一步,但仍然存在重要的开放问题。
如上所述,Parallel-R1(Zheng et al., 2025)将 APR 呈现为一种中期训练探索框架,而非主要是推理时技术。这引出了一个更根本的问题:推理时的并行化是持续提高准确率,还是主要作为一种训练时的探索框架有价值?Parallel-R1 暗示,RL 期间并行结构带来的多样性可能比测试时并行化本身更重要。
一个相关问题是稳定性。当并行化奖励放宽时,模型存在持续退回到顺序推理的倾向。Parallel-R1 的作者展示,在 200 步后移除并行化奖励会导致模型恢复到顺序行为。这是一个训练稳定性问题、奖励信号设计问题,还是并行结构确实与自回归预训练塑造的模型先验相冲突的证据?
除了 APR 是否有效之外,部署也带来了自己的问题。我们能否设计出在推理时考虑可用计算预算的训练方法,使并行化决策是硬件感知的,而非纯粹由问题驱动?
最后,上述考虑的并行结构本质上是扁平的。如果我们允许并行化深度大于 1 呢?递归语言模型(RLMs; Zhang, Kraska and Khattab, 2026)有效管理长上下文,并展示了有前景的推理时扩展能力。当用激励自适应并行化的端到端 RL 训练时,RLM 的表现如何?
致谢
感谢 Nicholas Tomlin 和 Alane Suhr 提供有益的反馈。感谢 Christopher Park、Karl Vilhelmsson、Nyx Iskandar、Georgia Zhou、Kaival Shah 和 Jyoti Rani 提出富有洞见的建议。感谢 Vijay Kethana、Jaewon Chang、Cameron Jordan、Syrielle Montariol、Erran Li 和 Anya Ji 进行宝贵的讨论。感谢 Jiayi Pan、Xiuyu Li 和 Alex Zhang 就自适应并行推理和递归语言模型提供建设性的通信交流。
原文:Adaptive Parallel Reasoning: The Next Paradigm in Efficient Inference Scaling — BAIR Blog, May 8, 2026
——
zhirenhun
一个热爱技术的程序员,喜欢分享前沿AI知识和开发经验。