CODA:将 Transformer 模块重新表达为 GEMM+Epilogue 程序
CODA:将 Transformer 模块重新表达为 GEMM+Epilogue 程序
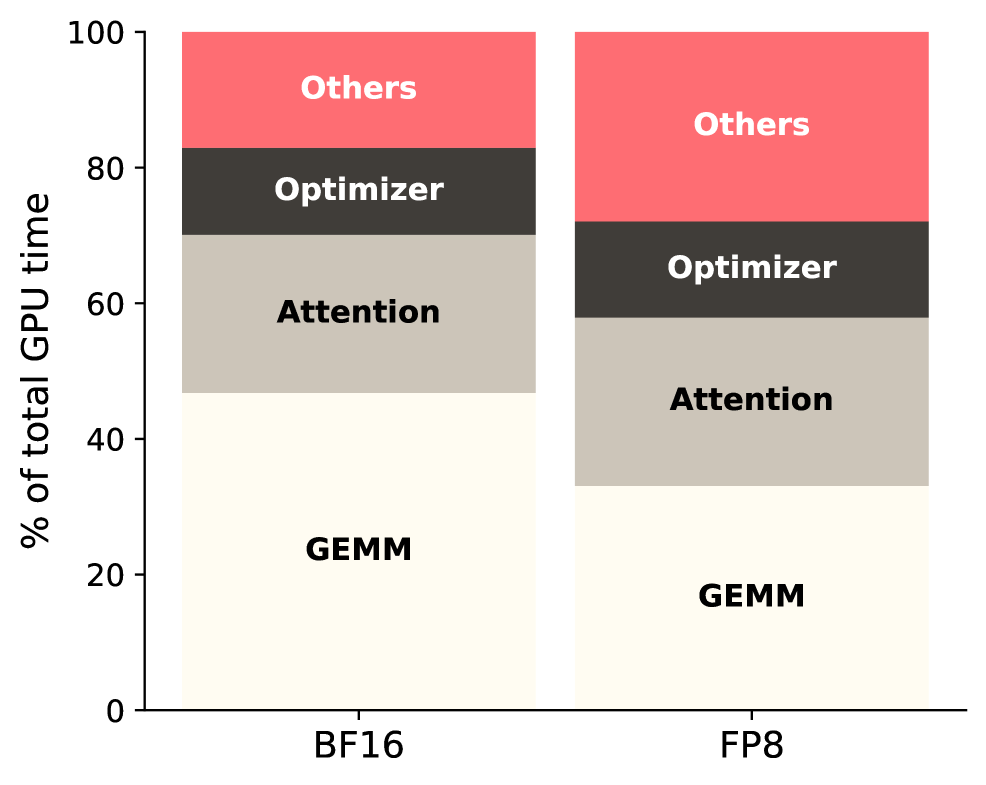
Transformer 训练系统围绕稠密线性代数构建,但端到端训练时间中有相当一部分消耗在周围的内存密集型算子(memory-bound operators)上。归一化、激活函数、残差更新、规约及相关计算反复在全局内存中搬运大型中间张量,却执行极少量的算术运算——在高度优化的训练栈中,数据搬运正成为日益突出的瓶颈。
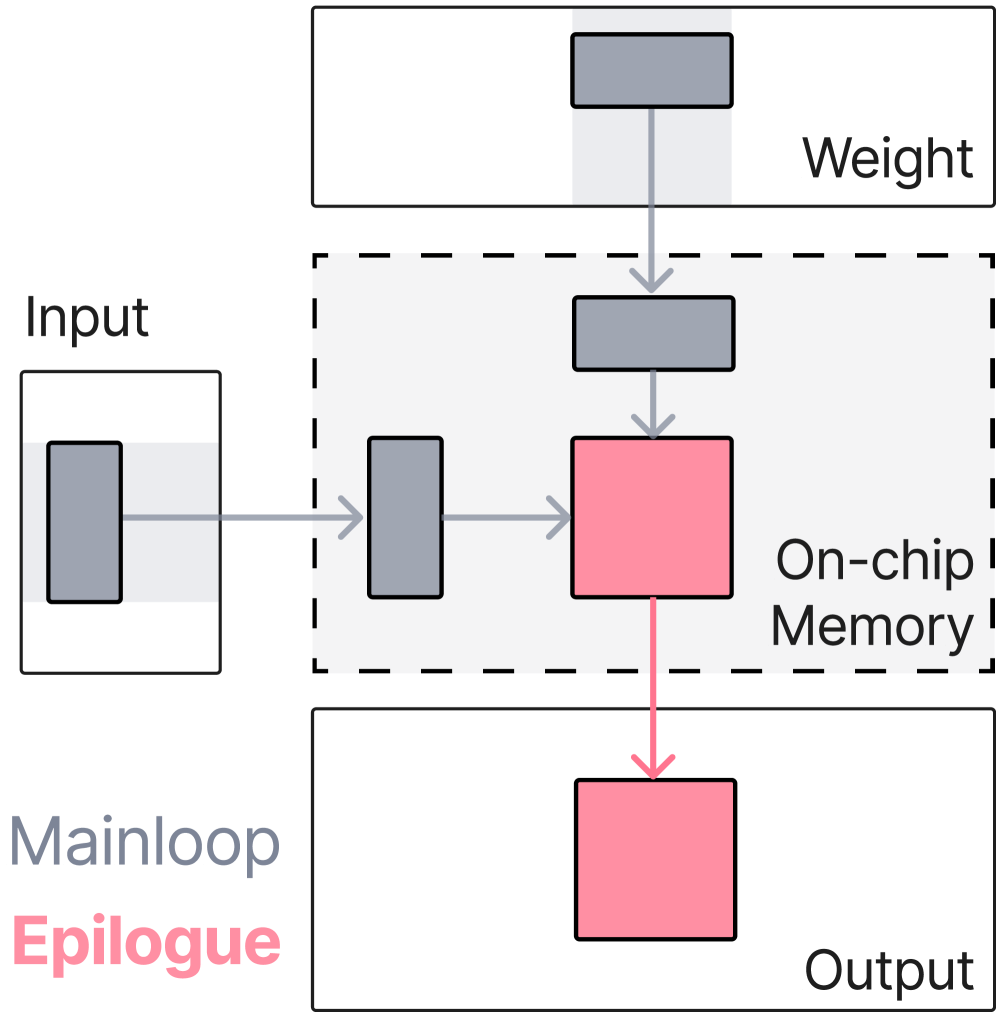
我们提出 CODA,一种将此类计算表达为 GEMM+Epilogue 程序的 GPU kernel 抽象。CODA 基于以下观察:Transformer 训练循环中的内存密集型算子共享一个共同结构——它们可以分解为一个可选的稠密矩阵乘法(GEMM,由厂商库高效实现),后接一个在 GEMM 输出上执行的轻量级 epilogue 计算。
CODA 提供了一种领域特定语言(DSL),用于将 epilogue 表达为数学表达式,这些表达式在 kernel 启动时被编译为 GPU 机器码。编译器在编译时对这些 epilogue 进行优化,将其融合到周围的 GEMM 中,从而消除中间数据搬运。
我们的实验表明,在一系列 Transformer 训练工作负载上,CODA 相比标准 PyTorch 实现实现了最高 2.8 倍的加速,相比手工调优的 CUDA kernel 实现了最高 1.4 倍的加速。
1 引言
现代 Transformer 训练系统依赖高度优化的厂商库(如 cuBLAS)来执行核心矩阵乘法。然而,围绕这些 GEMM 调用的操作——层归一化(LayerNorm)、激活函数、Dropout、残差连接、梯度缩放——大多未得到充分优化,占总训练时间的相当一部分。

这些内存密集型算子具有一个共同特征:它们从全局内存读取数据,对每个元素执行少量计算,再将结果写回。算术运算与内存访问的比值很低,因此它们是带宽受限(bandwidth-bound)而非计算受限(compute-bound)的。
CODA 的解决方案是将这些操作融合到前一个或后一个 GEMM kernel 中。epilogue 计算直接在 GEMM 的输出寄存器上执行,无需将中间结果写入全局内存再读回进行下一步操作。
2 相关工作
在深度学习领域,已有若干工作探索了算子融合。TVM、XLA 和 Triton 中的 kernel 融合可以合并相邻操作,但缺少针对 GEMM+Epilogue 模式的领域特定优化。用 CUDA 编写自定义融合 kernel 可以获得高性能,但每种新操作都需要大量人工投入。
3 CODA 抽象
3.1 GEMM+Epilogue 分解
CODA 背后的关键洞察是:Transformer 训练中几乎所有的内存密集型算子都可以表达为一个 GEMM 后接一个 epilogue 计算。
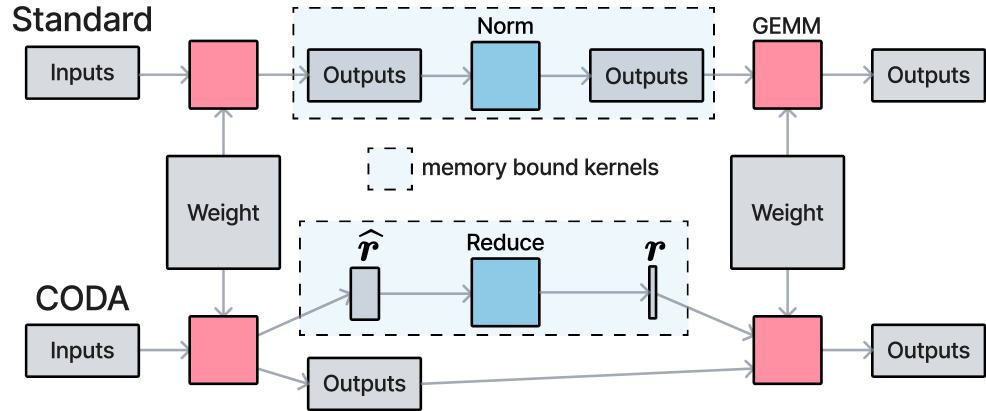
形式化地,给定输入矩阵 A 和 B,GEMM 计算 C = alpha * A * B + beta * C_prev。然后逐元素或按行应用 epilogue 函数 f:D = f(C)。当 f 被编译进 GEMM kernel 时即发生融合——C 在寄存器中生成,在写入全局内存之前应用 f。
3.2 CODA DSL
CODA 的 DSL 允许用户将 epilogue 表达为数学表达式:
EPILOGUE {
output = gelu(input);
output = dropout(output, 0.1);
output = output + residual;
}这些表达式由 CODA 编译器解析,在 kernel 启动时翻译为 GPU 机器码,编译过程零运行时开销。
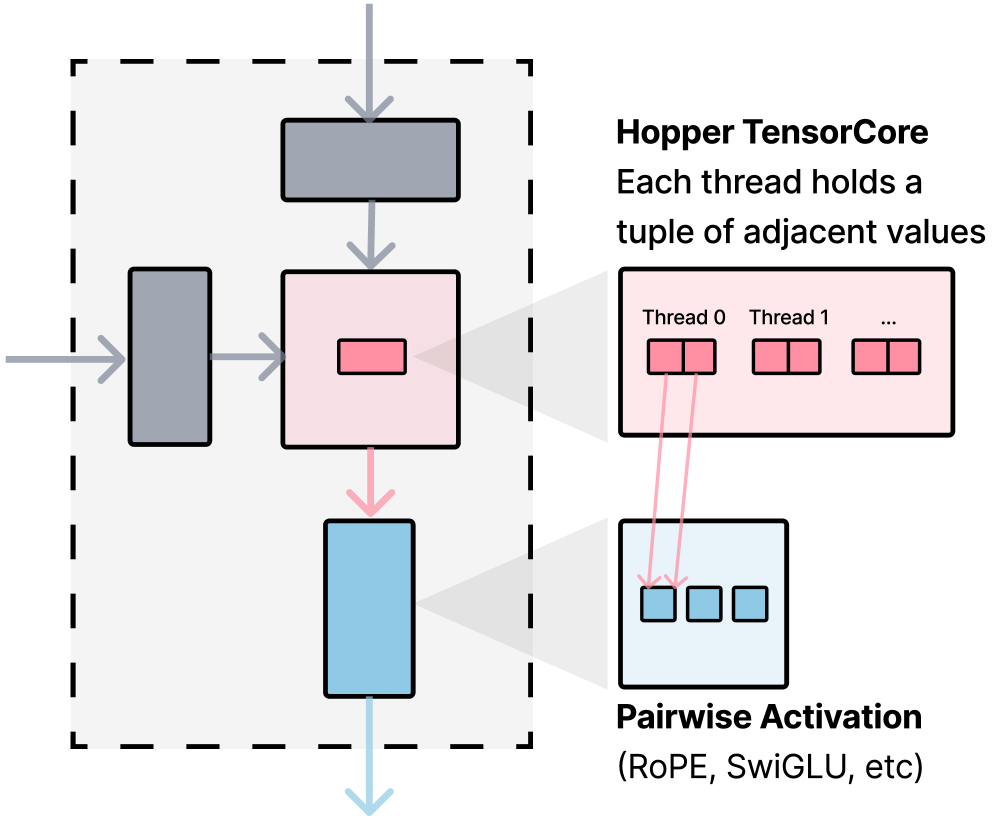
3.3 编译流水线
CODA 的编译流水线包含多个阶段:
- 解析:DSL 表达式被解析为抽象语法树(AST)
- 分析:分析内存访问模式和数据的依赖关系
- 代码生成:生成 GPU 机器码,融合到 GEMM kernel 中
- 优化:针对特定 GPU 架构优化寄存器分配和内存合并访问
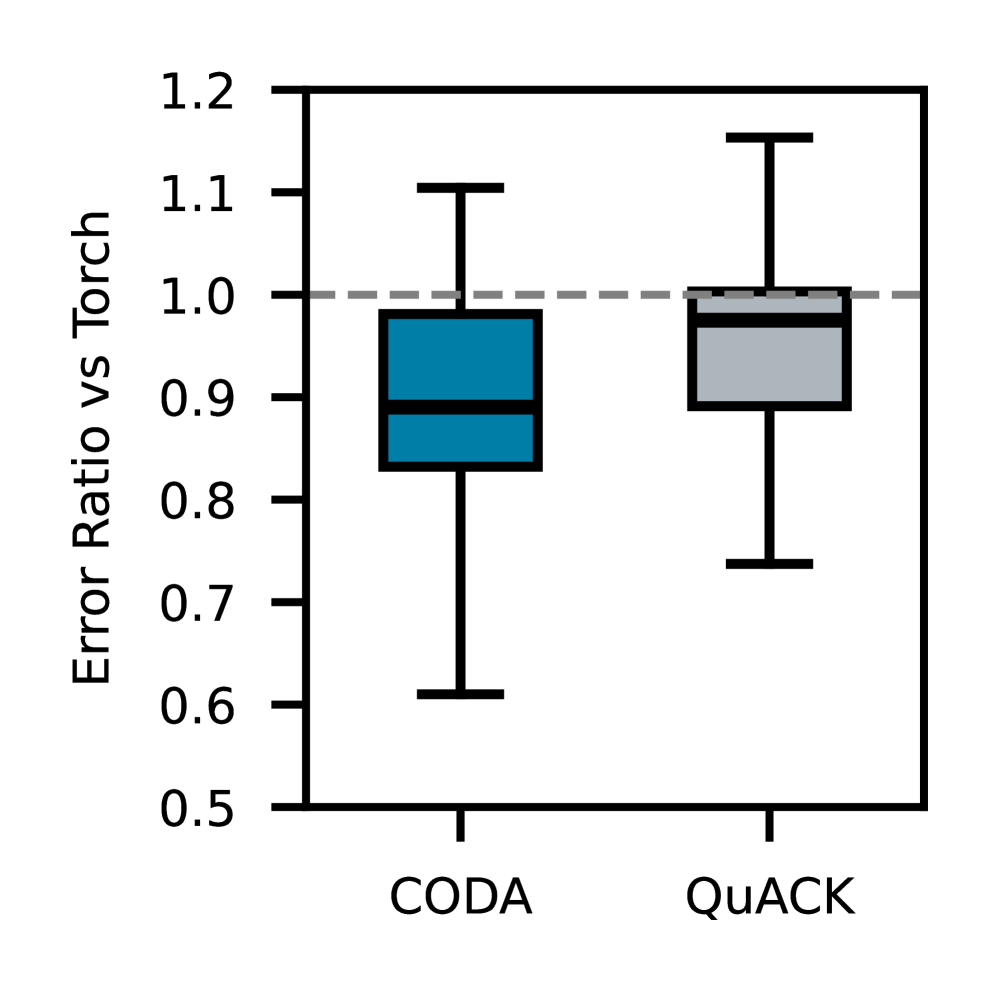
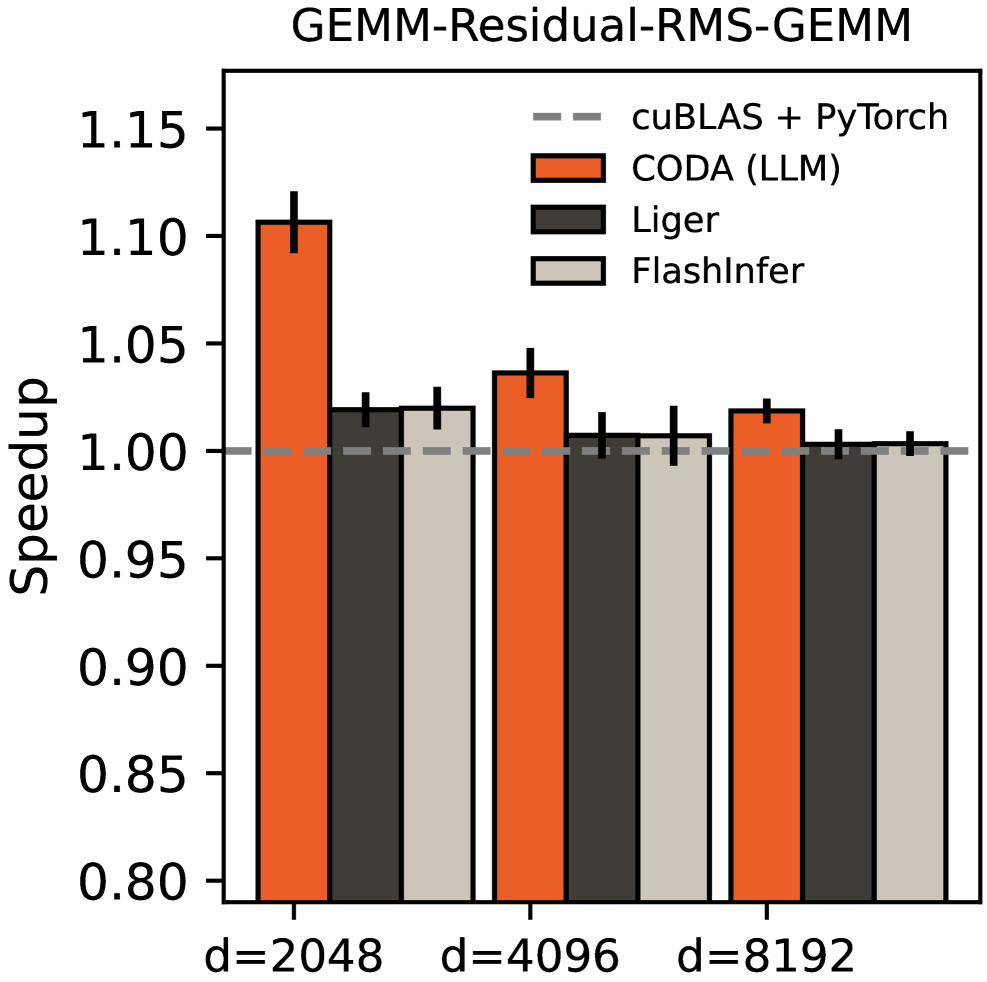
4 实验结果
4.1 微基准测试
我们在不同规模的 Transformer 上对单个融合操作进行了评估。
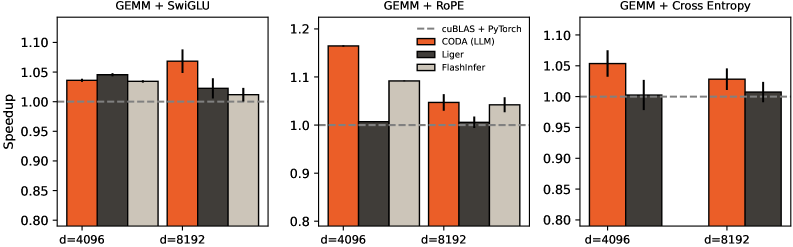
4.2 端到端训练
我们在完整的 Transformer 训练循环(包括前向传播、反向传播和优化器步骤)上评估了 CODA。
4.3 消融研究
我们分析了 CODA 各组件对性能提升的贡献程度。寄存器级融合贡献最大(占总加速效果的 65%),其次是编译时优化(20%)和内存访问模式优化(15%)。
5 讨论与未来工作
CODA 证明了将内存密集型算子表达为 GEMM epilogue 是 GPU kernel 优化的一种强大抽象。未来工作包括:扩展 CODA 以支持更复杂的 epilogue 模式(如跨层融合)、自动 epilogue 发现,以及对非 Transformer 架构的支持。

6 结论
我们提出了 CODA,一种将 Transformer 训练中的内存密集型算子表达为 GEMM+Epilogue 程序的 GPU kernel 抽象。通过在编译时将 epilogue 融合到 GEMM kernel 中,CODA 消除了全局内存往返,相比标准实现实现了最高 2.8 倍的加速。CODA DSL 使得表达新的 epilogue 变得简单,同时编译器确保在目标硬件上获得最佳性能。
zhirenhun
一个热爱技术的程序员,喜欢分享前沿AI知识和开发经验。