Moebius: 0.2B 轻量级图像修复框架,实现10B级别的性能
作者: Kangsheng Duan, Ziyang Xu, Wenyu Liu, Xiaohu Ruan, Xiaoxin Chen, Xinggang Wang
单位: 1 华中科技大学, 2 VIVO AI Lab
摘要: 尽管10B级别的工业级基础模型在图像修复领域取得了突破性进展,但其高昂的计算成本严重阻碍了实际部署。构建一个高度优化的任务特定专家模型是一个有前景的解决方案;然而,极端的结构压缩不可避免地会引发严重的表示瓶颈。为克服这一挑战,我们提出了 Moebius,一个高效的轻量级图像修复框架。我们通过引入局部-λ混合交互(LλMI)模块,系统性地重构了扩散骨干网络。该模块由局部-λ(Local-λ)和交互式-λ(Interactive-λ)模块组成,它巧妙地将空间上下文和全局语义先验信息总结到固定大小的线性矩阵中,在大幅削减参数的同时,保留了复杂的潜在交互。此外,为了释放这个高度紧凑架构的全部表示能力,我们将其与一种自适应多粒度蒸馏策略(adaptive multi-granularity distillation strategy)进行协同搭配。该策略严格在潜在空间内运行,避免了昂贵的像素空间解码,通过动态平衡多个基于梯度的损失函数,实现了高保真对齐。在自然场景和肖像基准测试上的广泛实验表明,这种最优协同作用使 Moebius 的生成质量能够匹敌甚至超越10B级别的工业通用模型 FLUX.1-Fill-Dev。值得注意的是,Moebius 使用的参数量不到其 FLUX.1-Fill-Dev 的2%(0.22B vs. 11.9B),同时将总推理时间加速了超过15倍,为高保真图像修复树立了新的效率标准。
方法 (Method)
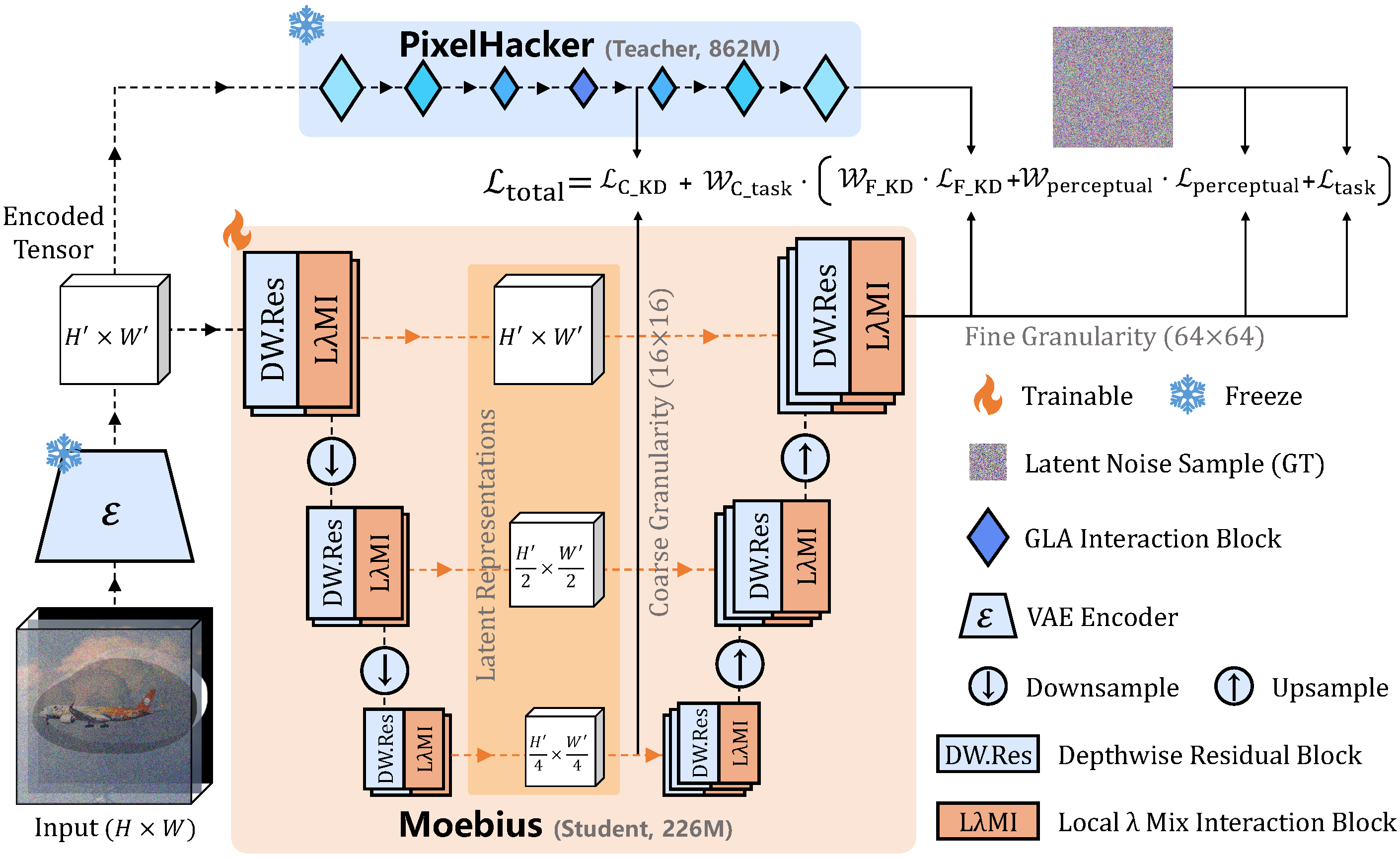
我们采用了配备了潜在类别引导(Latent Categories Guidance, LCG)的潜在扩散模型(Latent Diffusion Model, LDM)框架。为了实现极端的架构效率,我们使用所提出的 LλMI 模块系统性地重构了去噪 U-Net(详见第3.2节)。此外,我们在训练过程中应用了自适应多粒度蒸馏策略(第3.3节),将我们的轻量级专家模型与高容量的教师模型进行对齐,成功缓解了极端结构压缩导致的容量下降问题。
亮点 (Highlights)
- 📉 极端的参数效率(< 2%):
Moebius仅使用 0.22B(2.26亿)参数,仅占庞大工业巨头FLUX.1-Fill-Dev(11.9B)的不到2%。它打破了“重计算”的叙事,使高质量的图像修复能够在消费级和边缘设备上普及。 - ⚡ 15倍推理加速(26ms/步): 在单张GPU上实现了惊人的 26.01 ms/步 的推理延迟。结合优化的采样步数,
Moebius实现了比10B级别模型总运行时长超过 15倍 的加速。 - 🏆 10B级别的修复质量(匹敌/超越
FLUX.1-Fill-Dev): 模型尺寸的收缩并不意味着表示能力的退化。通过架构和蒸馏的协同优化,Moebius在涵盖自然场景(Places2)和肖像场景(CelebA-HQ, FFHQ)的6个综合基准测试中,性能与10B级别的SOTA通用模型(如FLUX.1-Fill-Dev,SD3.5 Large-Inpainting)持平,甚至在某些场景(如复杂纹理和面部真实感)中超越了它们。
💡 协同核心创新 (Synergistic Core Innovations)
- 架构设计(
LλMI模块): 它通过将空间上下文和全局语义先验信息压缩到固定大小的线性矩阵中,重构了自注意力(self-attention)和交叉注意力(cross-attention),从而绕过了二次方的计算开销。 - 自适应多粒度蒸馏策略: 它严格在潜在空间内转移来自我们的教师模型
PixelHacker的表示能力(避免了昂贵的像素空间解码)。它通过对多粒度监督(从微观中间特征到宏观扩散轨迹)进行对齐,并利用梯度范数自适应损失加权机制进行动态平衡,从而弥合了巨大的容量差距。 - 最优协同平衡: 我们系统地探索了紧凑结构与蒸馏之间的相互约束和上界。通过绘制这一架构-蒸馏协同作用的前沿,我们确保了 0.22B 的
Moebius(学生模型)能够吸收PixelHacker(教师模型)的最大语义推理能力,而不会触发表示饱和。 - 🚀 任务特定专家 vs. 臃肿的通用模型:
Moebius没有盲目地追求规模扩大,而是回答了一个根本问题:当任务明确时,模型能否更智能、更轻量、更快?
原文出处:Moebius Project Page | arXiv: 2606.19195