基于 Kolmogorov-Arnold 网络的 FPGA 超快机器学习
当大多数机器学习跑在 GPU 上时,亚微秒级延迟和高硬件效率的需求却暴露了 CPU/GPU 架构的根本局限。调度开销、指令优化和动态内存访问使得传统处理器无法满足极低延迟场景。FPGA 凭借其可重构的数字逻辑,成为自定义硬件加速的理想平台。
本文源自 Aarush Gupta 的硕士论文,该工作获得了 FPGA 2026 最佳论文奖及 ICML 2026 论文收录,展示了如何利用 Kolmogorov-Arnold 网络(KAN)在 FPGA 上实现纳秒级推理和亚微秒级在线学习。
FPGA 与 LUT:神经网络硬件化的基础
FPGA 的核心构件是查找表(LUT,Look-Up Table),这种数字逻辑单元可以高效实现任意布尔函数。与传统处理器顺序执行指令的方式不同,FPGA 将神经网络直接实现为数字逻辑电路——这不是在处理器上"运行"模型,而是将模型"变成"硬件本身。
然而,数字电路以比特为单位操作,这意味着连续数值必须经过量化才能被硬件处理。固定点量化使用 base-2 表示法,用指定数量的分数位来编码小数部分——精度与位宽之间的权衡直接决定了硬件资源的消耗。
LUT 神经网络与指数级增长的挑战
FPGA 的 LUT 本质上可以表示任意二元函数——通过学习连续函数并将其离散化转换为 LUT,可以存储每个输入组合对应的输出。这一思路直接催生了 LUT-NN(LUT 神经网络)。
但问题在于:当扩展到多元函数时,LUT 的大小会呈指数级增长($2^{d_i b_i}$)。一个具有 8 位输入和 8 位权重的 4 输入函数就需要 $2^{32}$ 个条目,这在任何 FPGA 上都是不切实际的。必须找到一种更高效的架构来驾驭 LUT 的表达能力。
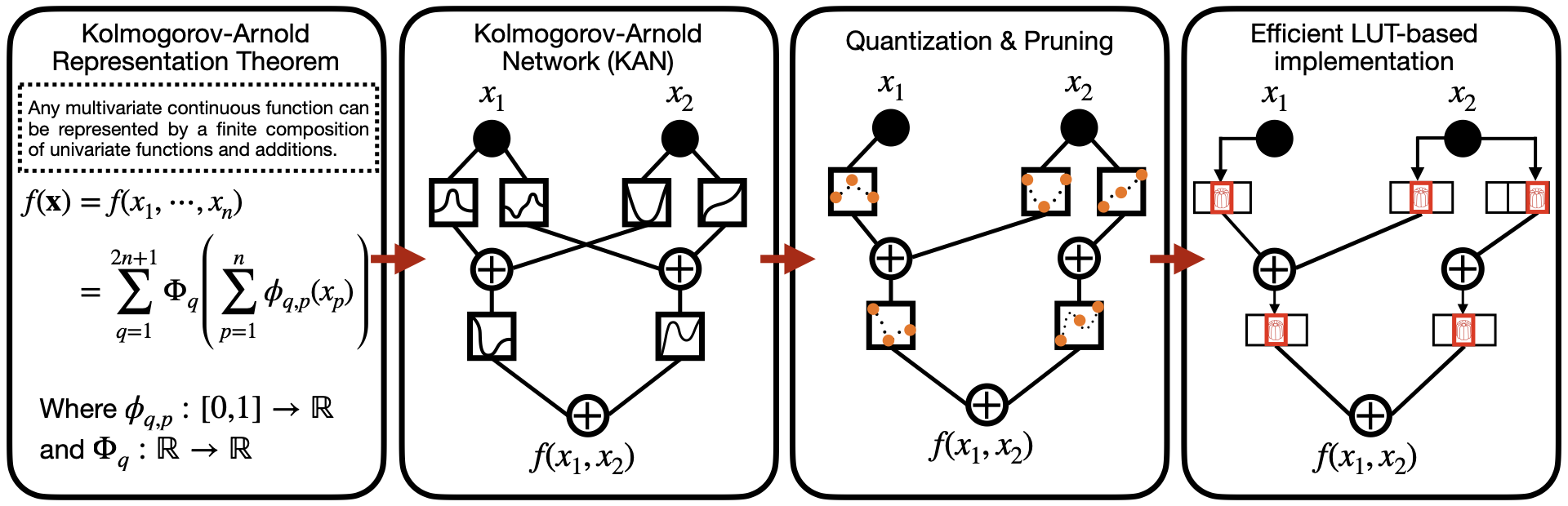
KAN:天然适配 LUT 的神经网络架构
Kolmogorov-Arnold 网络(KAN)为解决这一困境提供了优雅的方案。与传统的多层感知器(MLP)不同——后者使用固定激活函数和可学习的标量权重——KAN 用可学习的单变量边函数替代了 MLP 中的固定激活函数。
具体来说:
- KAN 的每条边携带一个可学习的单变量函数,而非一个标量权重
- 每个节点只是简单地对所有输入求和
- 网络的学习能力分布在边函数上,而非深度堆叠的层中
这种结构使得 KAN 成为 LUT-NN 的理想候选架构——单变量函数天然可以用小型 LUT 高效实现,避免了多变量函数的指数级爆炸问题。
从 B 样条到 LUT:可微训练与硬件映射
在实现中,边函数使用 B 样条(B-spline)参数化。B 样条具有良好的局部性和平滑性,可以在训练过程中通过反向传播进行可微优化。训练完成后,连续的 B 样条函数被离散化为 LUT,映射到 FPGA 硬件上。
每个激活函数在 FPGA 上用双重 LUT 实现:
- 粗粒度 LUT:覆盖函数的大致形状,使用较少区间
- 细粒度 LUT:在粗粒度基础上提供精细调整,提高精度
这种两层结构在硬件资源消耗和计算精度之间取得了良好的平衡。
实验结果:精度相当,速度飞跃
在多个分类和回归任务上的实验结果显示:
- 精度:相同参数量下,KAN-LUT 的精度达到或超过 MLP-LUT
- 推理延迟:FPGA 上的推理延迟仅 5-10 纳秒,比 GPU 推理快超过 1000 倍
- 资源消耗:远低于等效 GPU 推理所需的功耗和面积
这一速度提升的意义在于——当 GPU 推理的延迟还在微秒级别徘徊时,FPGA + KAN 的组合已经将推理推入了纳秒时代。这对于高频交易、实时控制、网络数据包处理等对延迟极度敏感的应用场景而言,意味着质的飞跃。
首次在 FPGA 上实现亚微秒在线学习
传统 FPGA 上的机器学习只能进行推理,无法训练——这严重限制了其在动态环境中的应用。本工作首次在 FPGA 上实现了真正的在线学习,使得模型可以在部署后持续更新。
关键技术突破包括:
- 利用 B 样条的局部性(spline locality):修改一个 region 的参数不会影响其他 region,使得梯度更新只需要聚焦于局部区域
- 局部基函数的高效梯度计算:利用 B 样条的局部支撑特性,大幅减少需要计算的梯度数量
- 稳定的定点训练算法:在有限的位宽下保证训练过程的数值稳定性
结果:FPGA 上实现了亚微秒级的梯度更新(<100ns),这是业界首次在 FPGA 上达成在线学习的实时能力。
结论:KAN + FPGA 开辟 ML 部署新方向
KAN 天然适合 FPGA 上的 LUT-NN 实现——它的单变量边函数结构完美匹配 LUT 的能力范围,避开了多变量 LUT 的指数级扩展问题。超快推理与在线学习的结合,为低延迟、高能效的机器学习部署开辟了全新的方向。
当 GPU 还在功耗和延迟之间艰难取舍时,KAN 驱动的 FPGA 方案已经证明:在特定场景下,我们既不需要牺牲精度,也不需要忍受延迟——两者可以兼得。
原文:Ultrafast machine learning on FPGAs via Kolmogorov-Arnold Networks