
如何阻止Claude说“承重”之类的话
如何阻止Claude说“承重”之类的话 2026年7月14日 2分钟阅读 claude llm parody 看到Claude把所有东西都称为“诚实看法”和“承重接缝”,你是不是气得抓狂?你不是一个人。但如果我告诉你,有一种方法可以把这种巨大的挫败感变得如此荒谬,让你忍不住笑出来呢?或者干脆直...

LogiChat:从问答对到文档RAG的架构重构
LogiChat 是一个聊天机器人(chatbot)平台。客户上传文档,获取聊天组件(chat widget),无需接触模型。过去两年里,“训练机器人”意味着在仪表盘表单中手动整理问答列表——question 和 answer 对,一次一行,作为少样本(few-shot)对注入提示词(prom...

AI时代的可观测性设计(第二部分):PII防护与自愈
_AI辅助声明:本文在Claude的协助下起草。所有技术内容、设计决策、代码引用和截图均反映我在airCloset设计并运行的生产系统;正文在发布前由我本人修订。_ 大家好,我是Ryan,airCloset的CTO。 在第一部分中,我介绍了四个监控轴(应用 / 基础设施 / CI / LLM)...
如何在不烧钱的情况下测试AI产品
如何在不烧钱的情况下测试AI产品 原文:https://dev.to/debs_obrien/how-we-test-an-ai-product-without-burning-credit-4c5p 大多数测试都很廉价。点击按钮,断言某些变化,运行一千次也无人察觉。但测试AI产品则不同,因为有趣

提示词为何失败(以及如何修正)
提示词为何失败(以及如何修正) 原文:https://dev.to/blobxiaoyao/why-your-prompts-fail-and-how-to-fix-them-1fb6 这里有一个可靠的测试方法:找一个效果不佳的提示词,仔细阅读。然后问自己——模型是在哪个具体句子获得了许可,从而做

你可能不需要向量数据库来做RAG
你可能不需要向量数据库来做RAG 来源:dev.to/arthurpro 提到“RAG”,脑海中会浮现一幅特定画面:一个嵌入模型、一个像Pinecone或pgvector这样的向量数据库,以及每次查询都要调用的嵌入API。这感觉就像入场券——真正的基础设施、真实的账单、实际的运维面——仅仅为了让
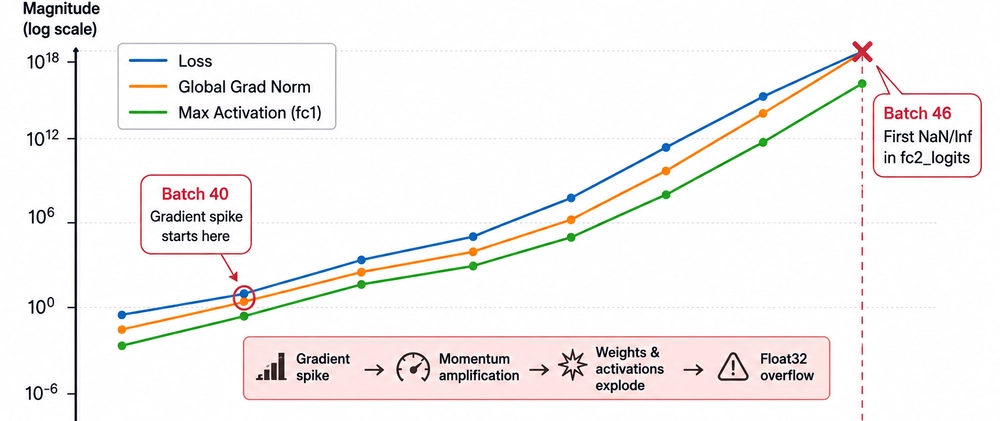
一个梯度尖峰,六批数据后出现NaN:调试确定性神经网络训练失败
一个梯度尖峰,六批数据后出现NaN:调试确定性神经网络训练失败 原文:https://dev.to/ertugrulmutlu/one-gradient-spike-six-batches-to-nan-debugging-a-deterministic-neural-network-trainin

Claude Code,超越提示——加固MCP数据库工具(第四部分深度解析)
Claude Code,超越提示——加固MCP数据库工具(第四部分深度解析) 原文:https://dev.to/gde03/claude-code-beyond-the-prompt-hardening-an-mcp-database-tool-part-4-deep-dive-299m 本文是

BrowserAct与Agent浏览器:一次实战隐匿执行对比
BrowserAct与Agent浏览器:一次实战隐匿执行对比 原文:https://dev.to/hadil/browseract-vs-agent-browser-a-hands-on-stealth-execution-comparison-b82 这是一次实操对比测试,我在相同条件下使用Sa

qMLX:通过极致优化Mac Studio最大化我的AI幻觉
qMLX:通过极致优化我的Mac Studio来最大化AI“精神病”体验 2026年7月10日·12分钟阅读 原文:https://mrzk.io/posts/qmlx-maximising-ai-psychosis-minmaxing-mac-studio/ 目录 为何更换模型 真正的工作:修