
qMLX:通过极致优化Mac Studio最大化我的AI幻觉
qMLX:通过极致优化我的Mac Studio来最大化AI“精神病”体验 2026年7月10日·12分钟阅读 原文:https://mrzk.io/posts/qmlx-maximising-ai-psychosis-minmaxing-mac-studio/ 目录 为何更换模型 真正的工作:修

Mesh LLM:基于iroh的分布式AI计算
Mesh LLM:基于iroh的分布式AI计算 2026年7月11日,作者:Rae McKelvey 当人们想象运行大型语言模型时,脑海中浮现的是数据中心——一排排属于他人的GPU、按量计费的API,以及随着业务成功而逐月增长的账单。你将提示词发送给一个黑盒,祈祷价格、模型和隐私政策都保持注册时的原

结构化输出 vs 工具使用 vs 预填充:2026年从Claude获取JSON
结构化输出 vs 工具使用 vs 预填充:2026年从Claude获取JSON 长期以来,强制模型输出JSON的技巧是在助手轮次中预填充一个左花括号。但这个技巧在当前版本的Claude模型上已经失效了,会返回400错误。如果你还在使用这种方法,一旦升级模型版本,代码就会崩溃。本文将介绍获取可靠结构化

在AWS Bedrock上构建生产级AI代理——值得关注的架构与代码决策
在AWS Bedrock上构建生产级AI代理——值得关注的架构与代码决策 原文:https://dev.to/aws-builders/building-production-ai-agents-on-aws-bedrock-architecture-and-code-decisions-worth
如何为你的AI代理构建评估框架(确保其在生产环境中不崩溃)
如何为你的AI代理构建评估框架(确保其在生产环境中不崩溃) 这个智能体通过了所有我手动测试的用例。然后有用户让它"预订更便宜的航班",它愉快地调用了错误航班ID的预订功能,整整三天没人发现——因为我一直在运行的演示从未要求过"更便宜的航班"。 这就是陷阱。当你亲自运行测试智能体时,演示本身就是测试—

我把一个仅限Claude Code使用的网页阅读器变成了一个普通的MCP服务器
我把一个仅限Claude Code使用的网页阅读器变成了一个普通的MCP服务器 我在用智能体构建应用时反复遇到同一个问题: 页面是公开的,浏览器能正常读取,但我的智能体却会被拦截、重定向、限流,或者只拿到一个空壳 HTML,毫无有用内容。 这个领域已经有一个有趣的项目:insane-search。它

你的 CS 学位没好好教你的数据结构
你的 CS 学位没好好教你的数据结构 每个计算机科学课程都会反复灌输七种基本数据结构:数组、链表、哈希表、栈、队列、图、树。你可能闭着眼睛都能背出它们的 Big O 复杂度——说真的,90% 的代码用这些足够了。
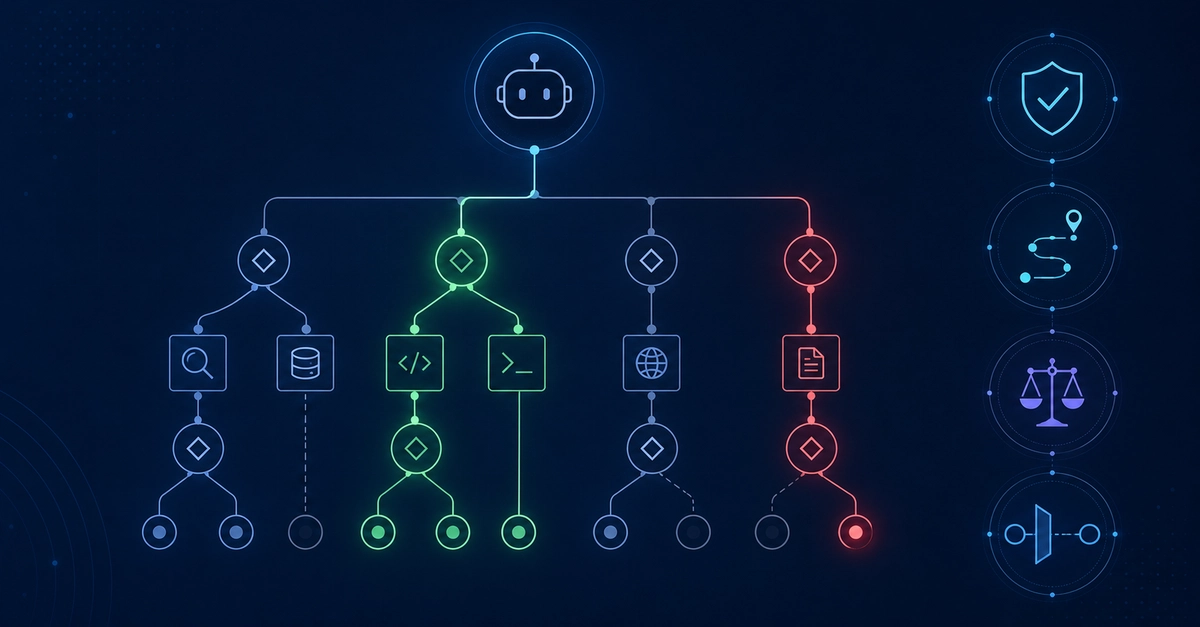
为你的 AI Agent 选择合适的工具层:MCP、CLI 还是 Skills?
为你的 AI Agent 选择合适的工具层:MCP、CLI 还是 Skills? 在软件工程中,选择正确的抽象层从来不是新问题。太抽象会让用户跳太多圈子(想想那些让人崩溃的 MiddlewareManagerAbstractFactoryProvider),太具体又会让重复代码满天飞。

更大的上下文窗口,并没有让我们的 RAG 变得更聪明
我们不再用「能塞进 prompt 多少个 token」来衡量检索质量。 长上下文模型出现后,很多人都做了同样的假设——如果 LLM 能读 128K token,检索似乎就没那么重要了。何必费心筛选文档,让模型直接读全部不就行了? 听起来合理,但实践中完全不是这么回事。
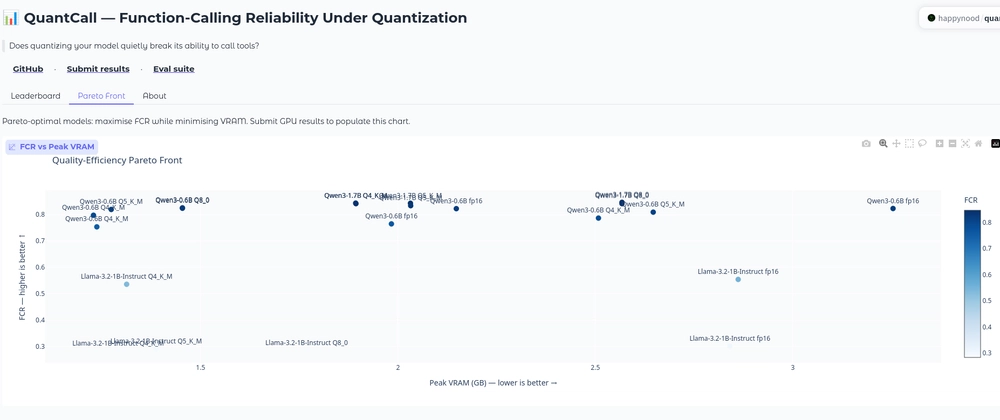
量化会破坏 LLM 工具调用能力吗?在4GB笔记本GPU上的实测报告
"Q4 对工具调用安全吗?"这个问题在本地 LLM 圈子中反复被提起,而答案几乎都是基于个例的推测。作者在 4GB 笔记本 GPU 上构建了 QuantCall 基准测试,用 bootstrap 方法严谨测量了量化对不同模型工具调用能力的影响。